

苹果卷开源大模型,公开代码、权重、数据集、训练全过程,OpenELM亮相
苹果卷开源大模型,公开代码、权重、数据集、训练全过程,OpenELM亮相要说 ChatGPT 拉开了大模型竞赛的序幕,那么 Meta 开源 Llama 系列模型则掀起了开源领域的热潮。在这当中,苹果似乎掀起的水花不是很大。
来自主题: AI技术研报
10161 点击 2024-04-25 17:17
要说 ChatGPT 拉开了大模型竞赛的序幕,那么 Meta 开源 Llama 系列模型则掀起了开源领域的热潮。在这当中,苹果似乎掀起的水花不是很大。

科幻大片中的AR黑科技,竟走进了现实! 就在刚刚,Meta自家的雷朋智能眼镜,已经开始支持多模态版的Llama 3了!要知道,Llama 3的开源版本还没支持多模态呢。
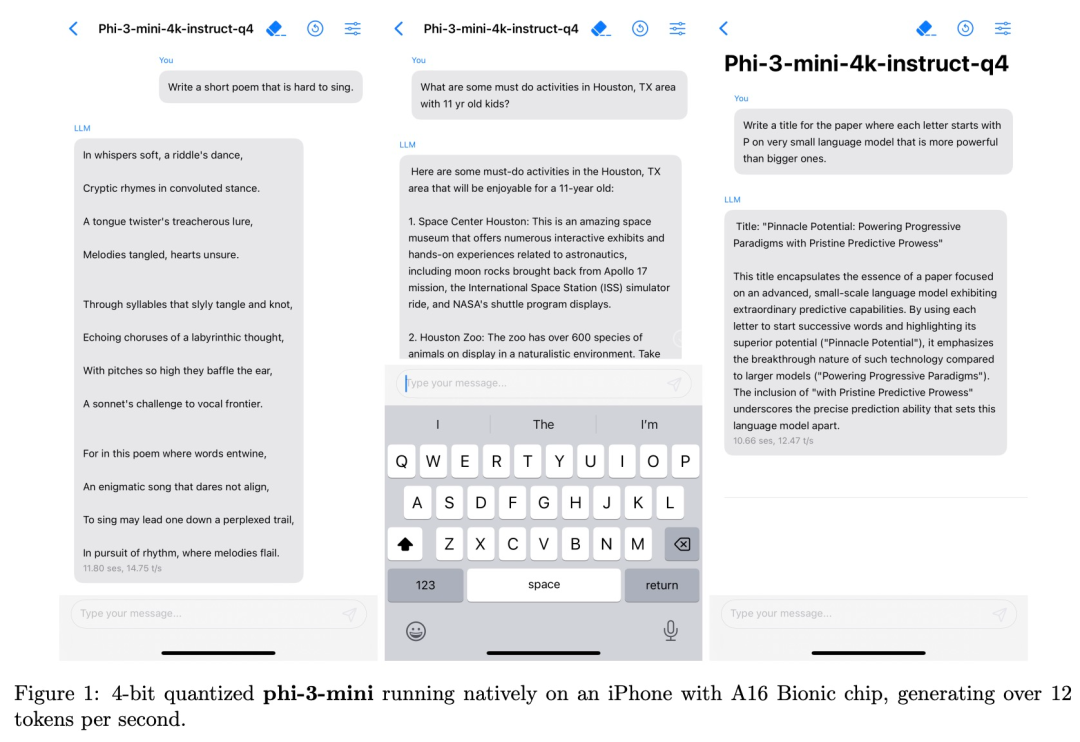
Llama-3 刚发布没多久,竞争对手就来了,而且是可以在手机上运行的小体量模型。
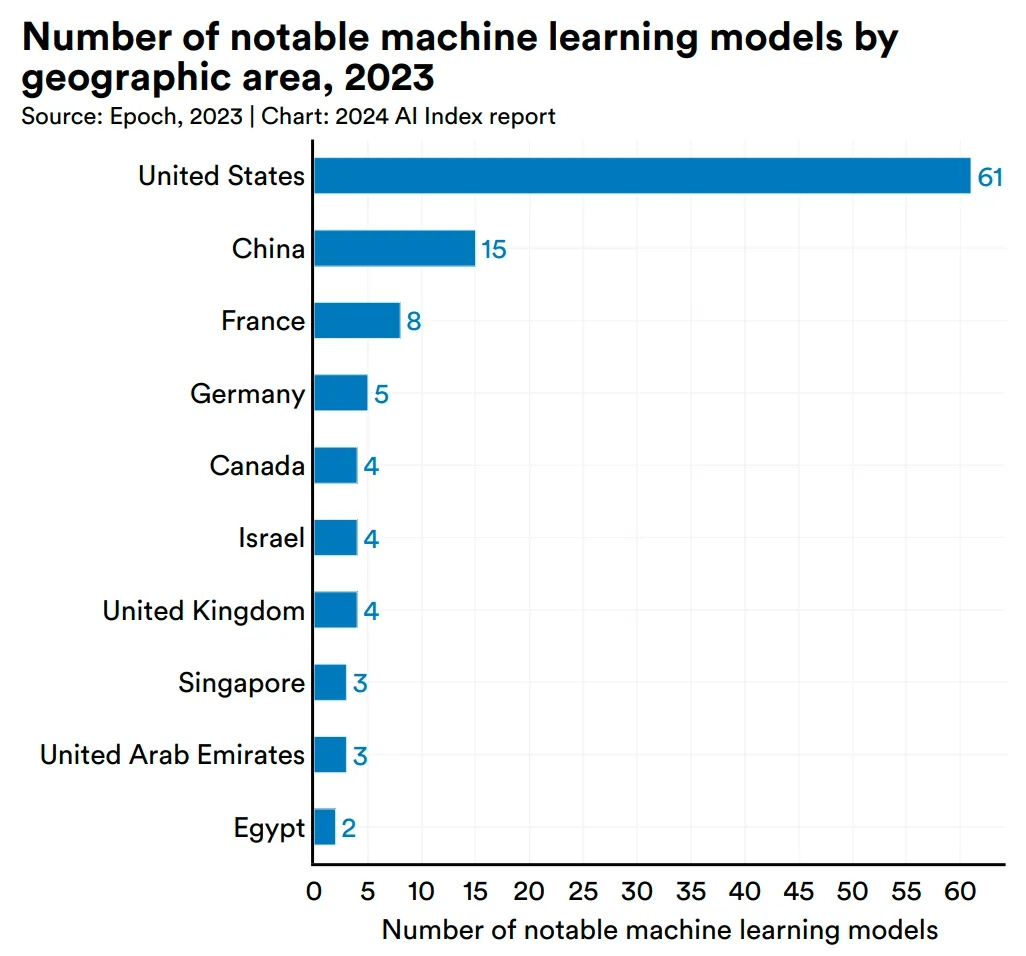
李彦宏说开源模型将越来越落后,然后Llama 3发布了。

这段时间,AI模型界是真的热闹,新的模型不断涌现,不管是开源还是闭源,都在刷新成绩。就在前几天,Meta就上演了一出“重夺开源铁王座”的好戏。发布了Llama 3 8B和70B两个版本,在多项指标上都超越了此前开源的Grok-1和DBRX,成为了新的开源大模型王者。

Llama 3发布刚几天,微软就出手截胡了?
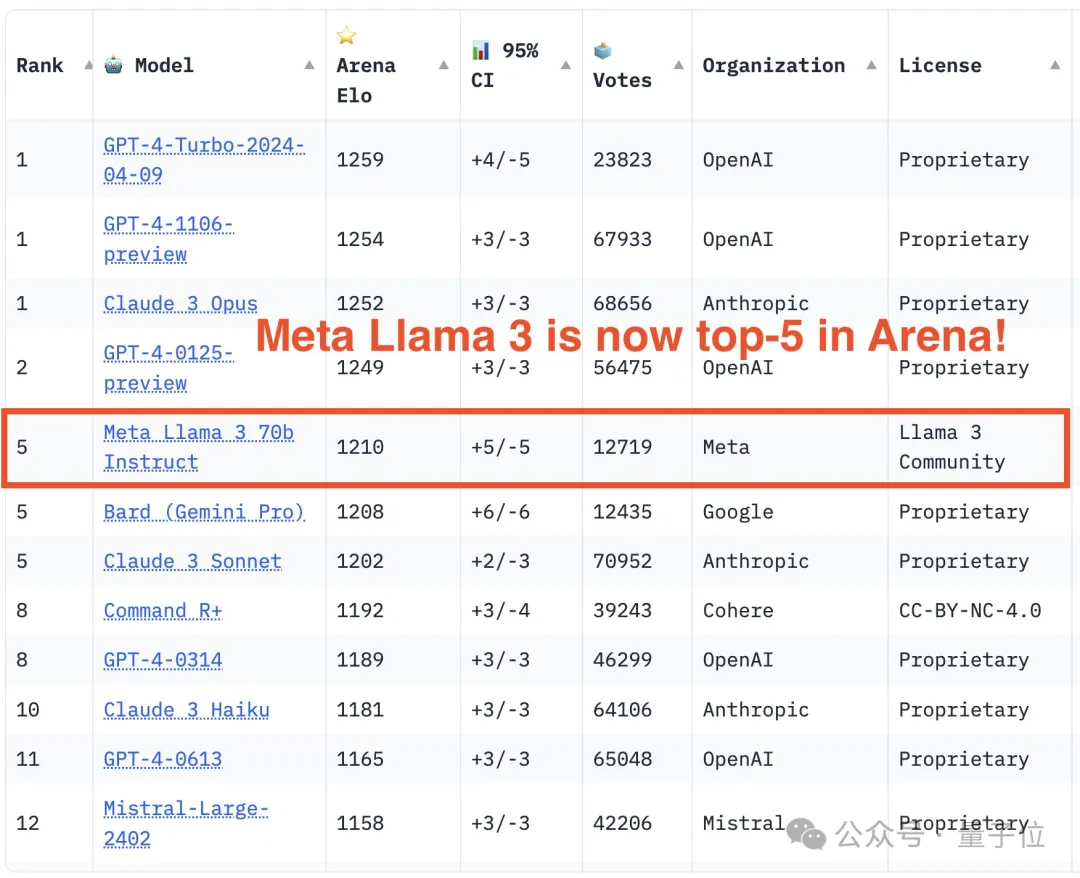
关于Llama 3,又有测试结果新鲜出炉—— 大模型评测社区LMSYS发布了一份大模型排行榜单,Llama 3位列第五,英文单项与GPT-4并列第一。
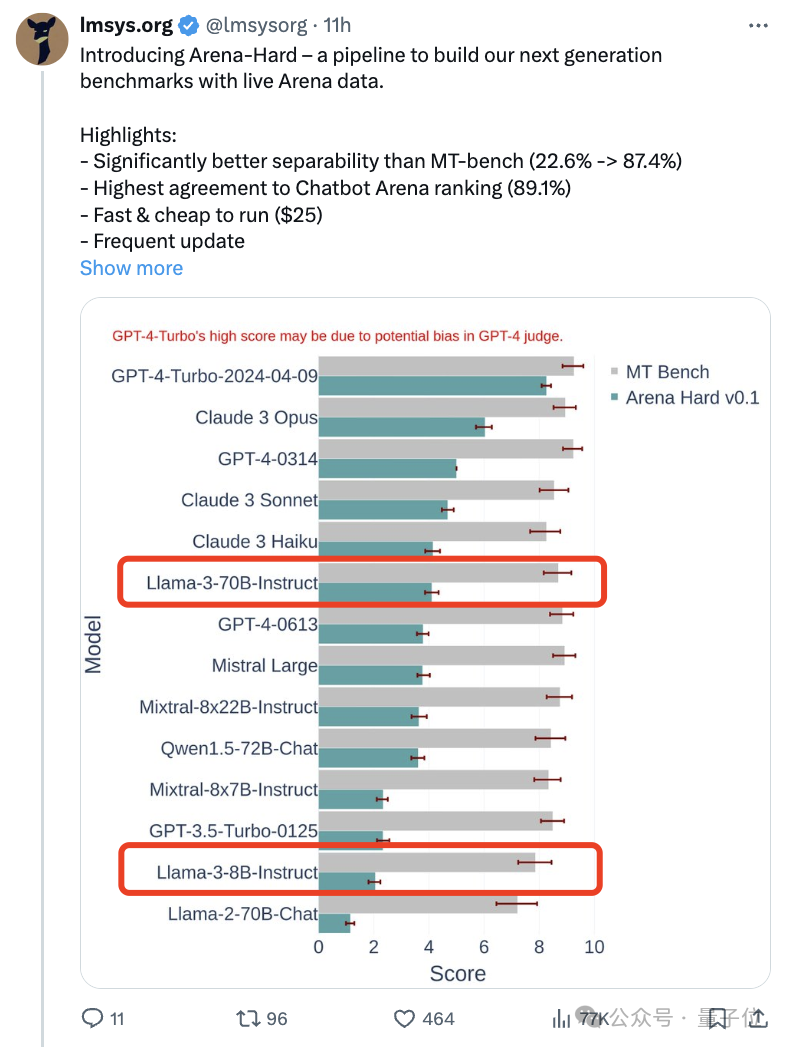
随着Claude 3、Llama 3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。

Llama 3诞生之后便艳压群雄,开源界已无「模」能敌。

就在刚刚,Meta官网上新,官宣了Llama 3 80亿和700亿参数版本