

Llama提速500%!谷歌美女程序员手搓矩阵乘法内核
Llama提速500%!谷歌美女程序员手搓矩阵乘法内核近日,天才程序员Justine Tunney发推表示自己更新了Llamafile的代码,通过手搓84个新的矩阵乘法内核,将Llama的推理速度提高了500%!
来自主题: AI技术研报
5992 点击 2024-04-07 17:49
近日,天才程序员Justine Tunney发推表示自己更新了Llamafile的代码,通过手搓84个新的矩阵乘法内核,将Llama的推理速度提高了500%!

在大模型落地应用的过程中,端侧 AI 是非常重要的一个方向。近日,斯坦福大学研究人员推出的 Octopus v2 火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行,在准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。

关注 OpenAI核心创始成员Andrej Karpathy 深度分享AI大模型发展及Elon管理法则。近日,OpenAI核心创始成员Andrej Karpathy(已于24年2月离职)在红杉资本进行了一场精彩的分享。
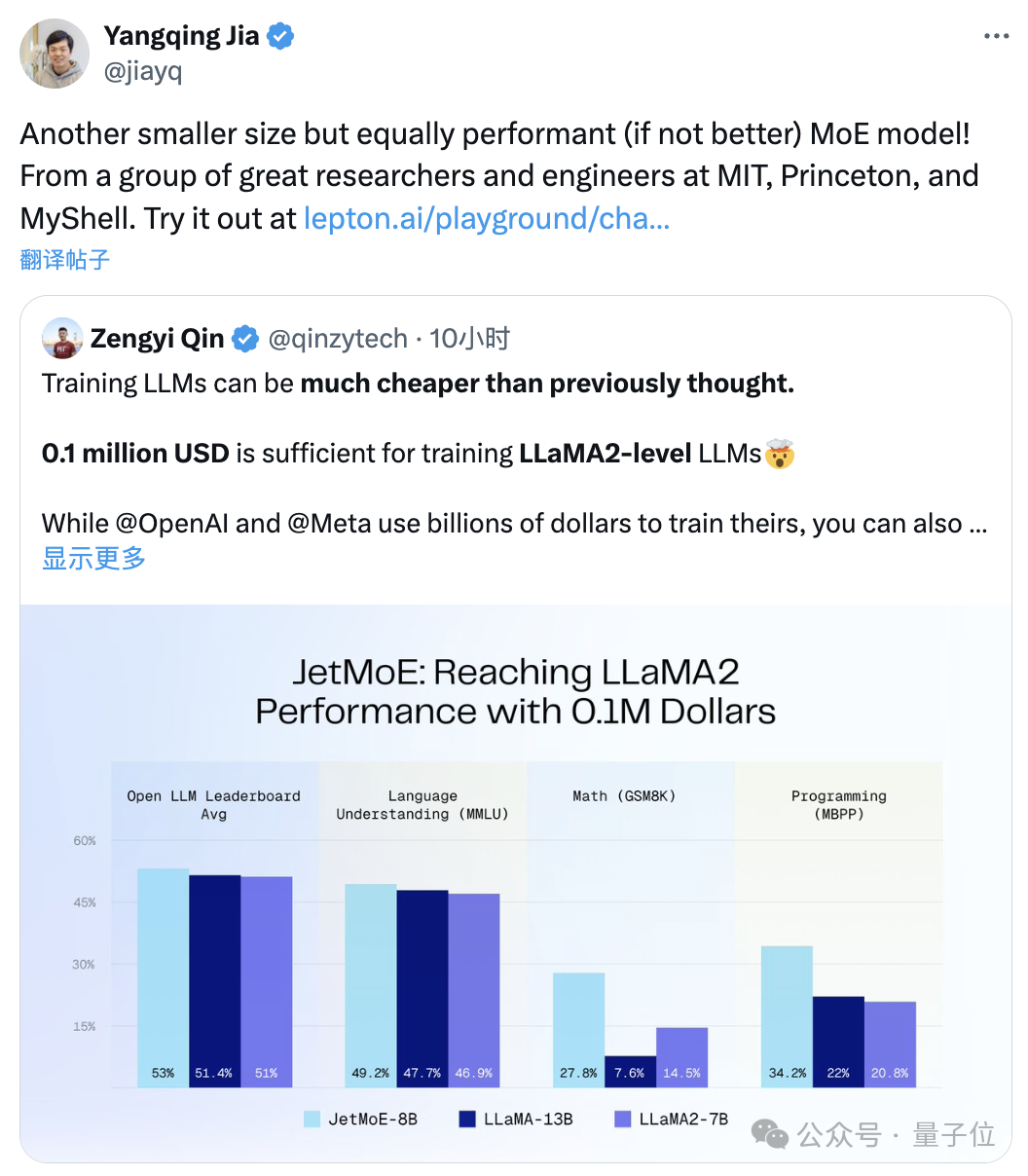
“只需”10万美元,训练Llama-2级别的大模型。尺寸更小但性能不减的MoE模型来了:它叫JetMoE,来自MIT、普林斯顿等研究机构。性能妥妥超过同等规模的Llama-2。

基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。
Anthropic 发现一种新型越狱漏洞并给出了高效的缓解方案,可以将攻击成功率从 61% 降至 2%。
大模型厂商在上下文长度上卷的不可开交之际,一项最新研究泼来了一盆冷水——Claude背后厂商Anthropic发现,随着窗口长度的不断增加,大模型的“越狱”现象开始死灰复燃。无论是闭源的GPT-4和Claude 2,还是开源的Llama2和Mistral,都未能幸免。
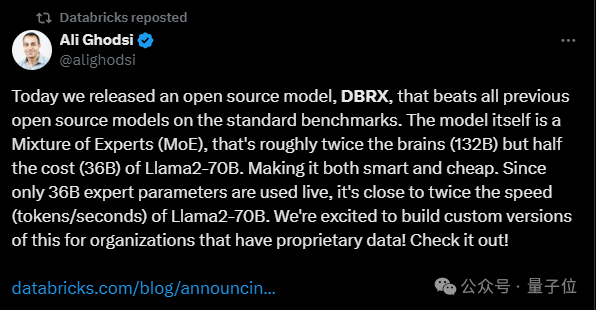
“最强”开源大模型之争,又有新王入局:

【新智元导读】就在刚刚,全球最强开源大模型王座易主,创业公司Databricks发布的DBRX,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。

这是迄今为止最强大的开源大语言模型,超越了 Llama 2、Mistral 和马斯克刚刚开源的 Grok-1。