
突破视频多模态大模型瓶颈!「合成数据」立大功,项目已开源
突破视频多模态大模型瓶颈!「合成数据」立大功,项目已开源视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。
来自主题: AI技术研报
5607 点击 2024-10-21 14:33
 搜索
搜索
视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。
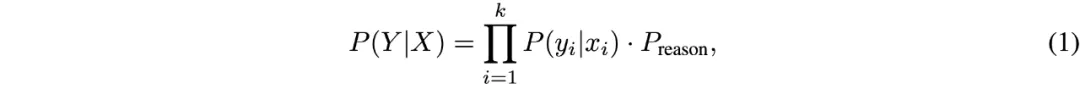
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。
最近,多模态大模型(LMM)取得了一系列引人注目的成就,特别是在视觉 - 语言任务上的表现令人瞩目。它们的成功不仅展现了多模态大模型在各个领域的实用性和灵活性,也为更多视觉场景下的应用探索了新的道路。

华中科技大学联合华南理工大学、北京科技大学等机构的研究人员对14个主流多模态大模型进行了全面测评,涵盖5个任务,27个数据集。

近期,随着多模态大模型(LMM) 的能力不断进步,评估 LMM 性能的需求也日益增长。与此同时,在中文环境下评估 LMM 的高级知识和推理能力的重要性更加突出。