

全球首个「视频教学」基准!南洋理工、CMU发布Video-MMMU
全球首个「视频教学」基准!南洋理工、CMU发布Video-MMMU人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
来自主题: AI技术研报
6847 点击 2025-02-12 12:01
人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
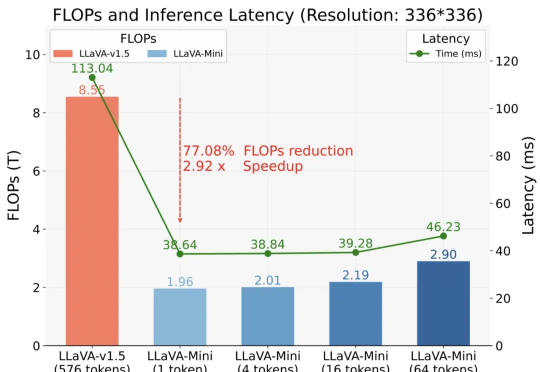
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。

华中科技大学联合华南理工大学、北京科技大学等机构的研究人员对14个主流多模态大模型进行了全面测评,涵盖5个任务,27个数据集。