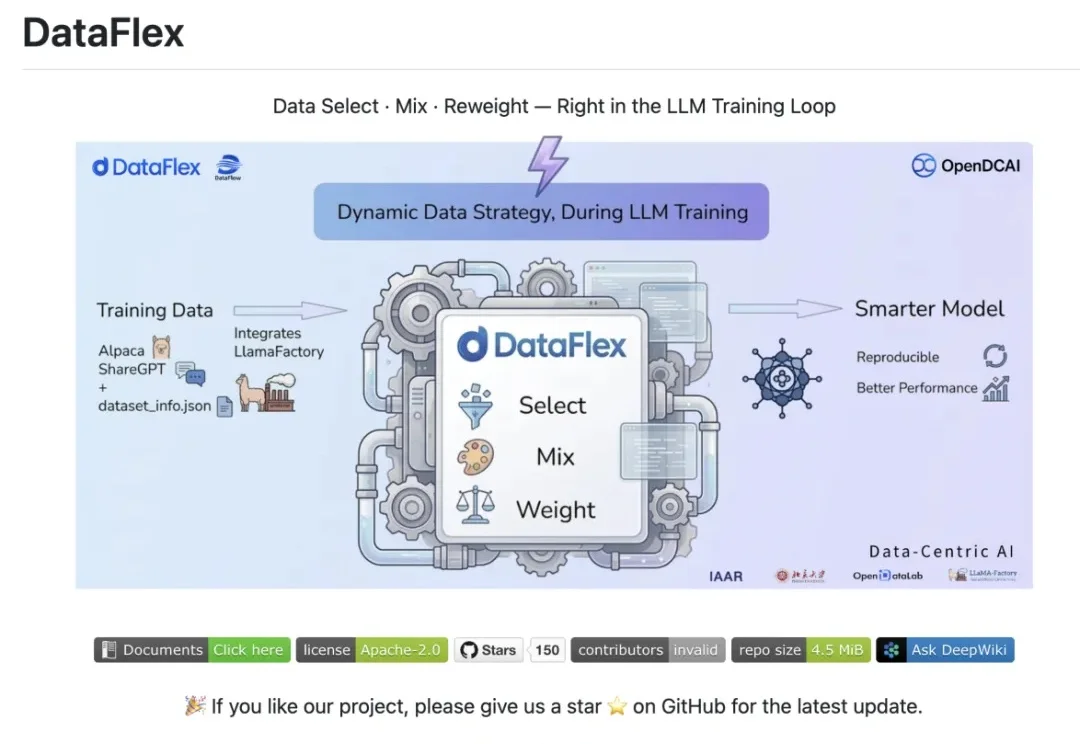
速递|开源AI模型运行工具Ollama融资6500万美元,团队仅14人,月活890万开发者
速递|开源AI模型运行工具Ollama融资6500万美元,团队仅14人,月活890万开发者流行的开源人工智能工具 Ollama 完成了 6500 万美元的 B 轮融资,由 Theory Ventures 领投,创始人兼首席执行官 Jeff Morgan 告诉 TechCrunch。Ollama 于 2023 年推出,帮助开发者在其个人电脑上运行开源权重的 AI 模型,让它们在数分钟内即可启动运行。
来自主题: AI资讯
9162 点击 2026-07-10 11:09