
华为:让DeepSeek的“专家们”动起来,推理延迟降10%!
华为:让DeepSeek的“专家们”动起来,推理延迟降10%!要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。
来自主题: AI技术研报
9797 点击 2025-05-20 15:16
 搜索
搜索
要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。

部署超大规模MoE这件事,国产芯片的推理性能,已经再创新高了—— 不仅是“英伟达含量为0”这么简单,更是性能全面超越英伟达Hopper架构!
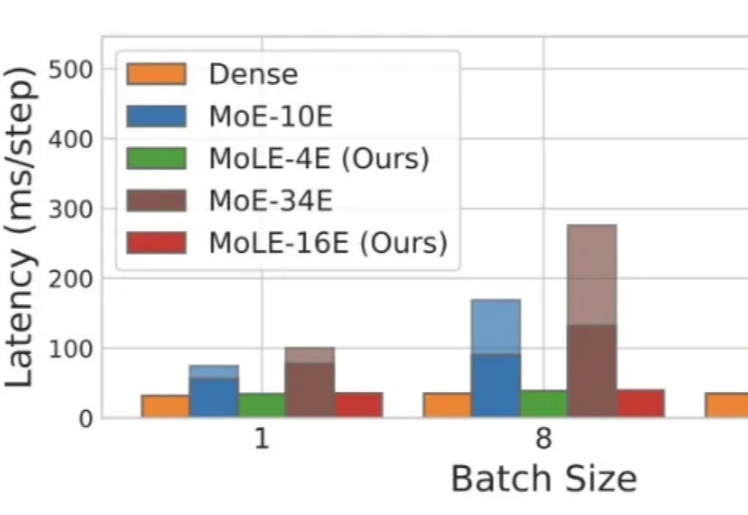
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。

研究揭示早融合架构在低计算预算下表现更优,训练效率更高。混合专家(MoE)技术让模型动态适应不同模态,显著提升性能,堪称多模态模型的秘密武器。

阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。

4 月 14 日,谷歌首席科学家 Jeff Dean 在苏黎世联邦理工学院举办的信息学研讨会上发表了一场演讲,主题为「AI 的重要趋势:我们是如何走到今天的,我们现在能做什么,以及我们如何塑造 AI 的未来?」
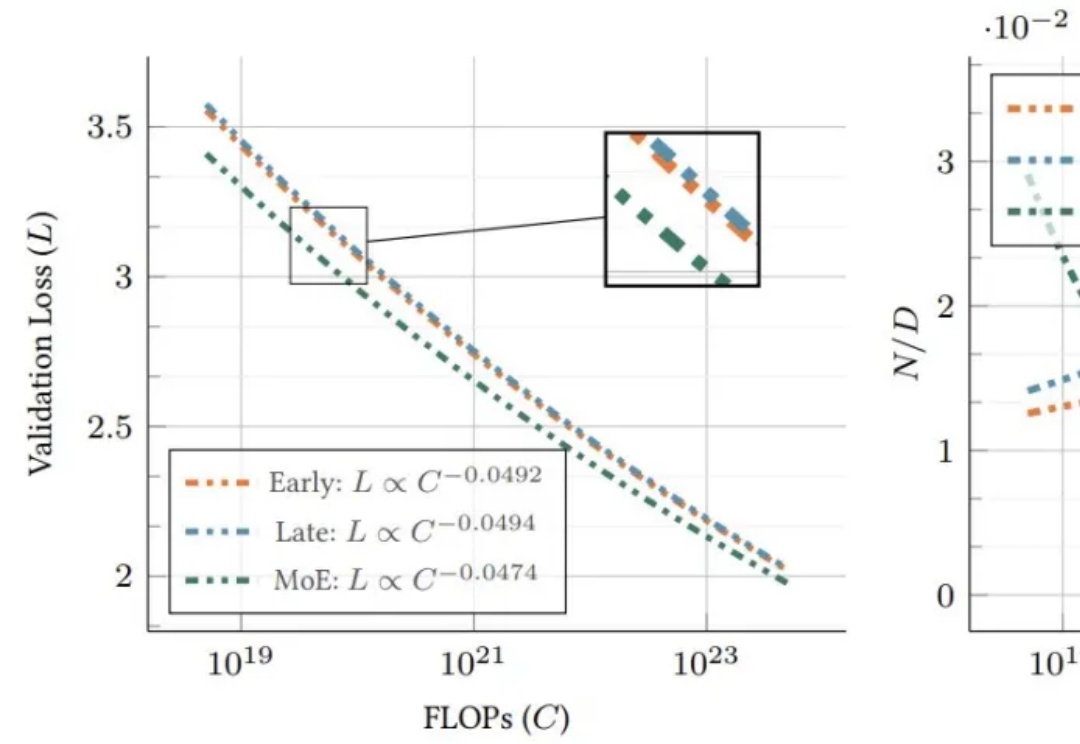
让大模型进入多模态模式,从而能够有效感知世界,是最近 AI 领域里人们一直的探索目标。

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。

字节跳动豆包团队今天发布了自家新推理模型 Seed-Thinking-v1.5 的技术报告。从报告中可以看到,这是一个拥有 200B 总参数的 MoE 模型,每次工作时会激活其中 20B 参数。其表现非常惊艳,在各个领域的基准上都超过了拥有 671B 总参数的 DeepSeek-R1。有人猜测,这就是字节豆包目前正在使用的深度思考模型。

商汤最新升级的日日新SenseNova V6解锁的新能力—— 原生多模态通用大模型,采用6000亿参数MoE架构,实现文本、图像和视频的原生融合。从性能评测来看,SenseNova V6已经在纯文本任务和多模态任务中,多项指标均已超越GPT-4.5、Gemini 2.0 Pro,并全面超越DeepSeek V3: