
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B刚刚,Kimi团队上新了!
来自主题: AI技术研报
8387 点击 2025-04-10 16:25
 搜索
搜索
刚刚,Kimi团队上新了!
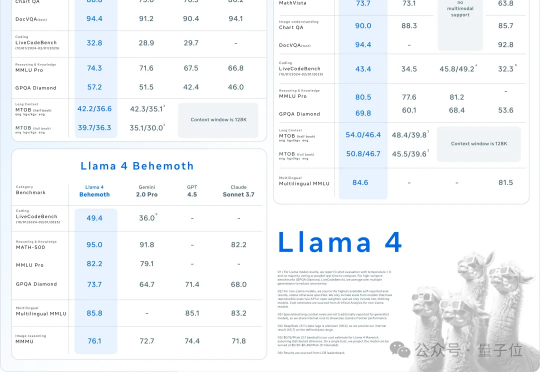
AI不过周末,硅谷也是如此。大周日的,Llama家族上新,一群LIama 4就这么突然发布了。这是Meta首个基于MoE架构模型系列,目前共有三个款:Llama 4 Scout、Llama 4 Maverick、Llama 4 Behemoth。

通过完全启用并发多块执行,支持任意专家数量(MAX_EXPERT_NUMBER==256),并积极利用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE Align & Sort逻辑被精心设计,实现了显著的性能提升:A100提升3倍,H200提升3倍,MI100提升10倍,MI300X/MI300A提升7倍...
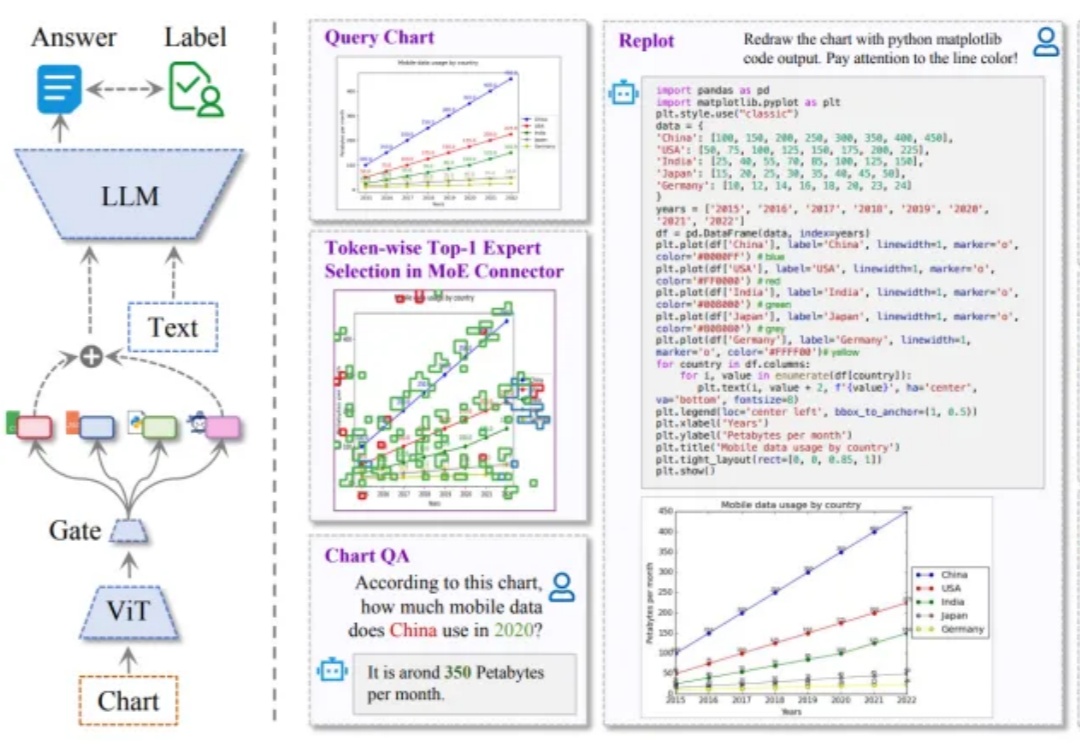
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%

当你翻开相册,看到一张平淡无奇的风景照,是否希望它能更温暖、更浪漫,甚至更忧郁?现在,EmoEdit 让这一切成为可能 —— 只需输入一个简单的情感词,EmoEdit 便能巧妙调整画面,使观众感知你想传递的情感。
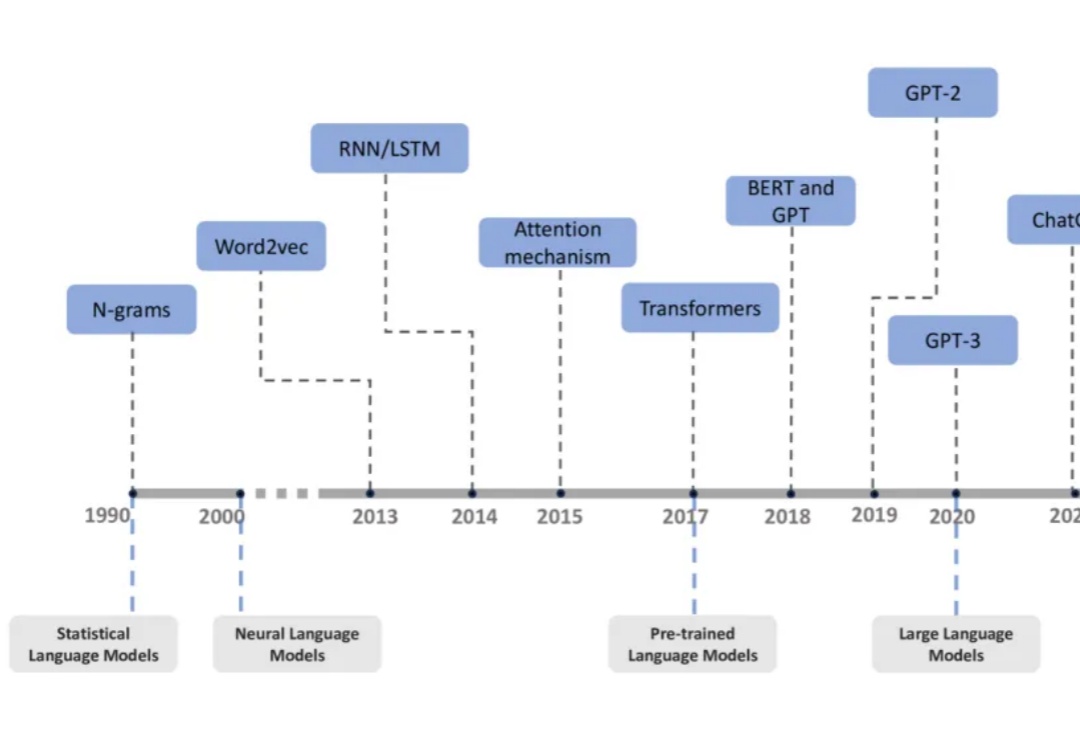
过去十年,自然语言处理领域经历了从统计语言模型到大型语言模型(LLMs)的飞速发展。

事关路由LLM(Routing LLM),一项截至目前最全面的研究,来了——
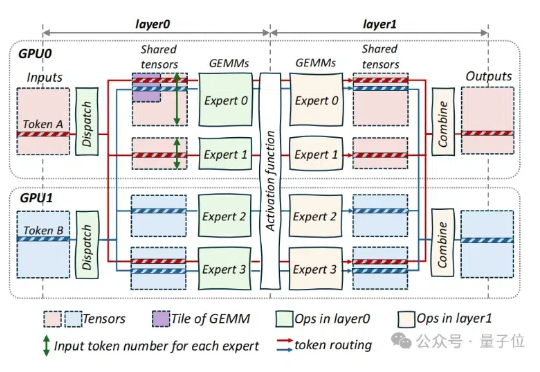
字节对MoE模型训练成本再砍一刀,成本可节省40%! 刚刚,豆包大模型团队在GitHub上开源了叫做COMET的MoE优化技术。
DeepSeek MoE“变体”来了,200美元以内,内存需求减少17.6-42%! 名叫CoE(Chain-of-Experts),被认为是一种“免费午餐”优化方法,突破了MoE并行独立处理token、整体参数数量较大需要大量内存资源的局限。
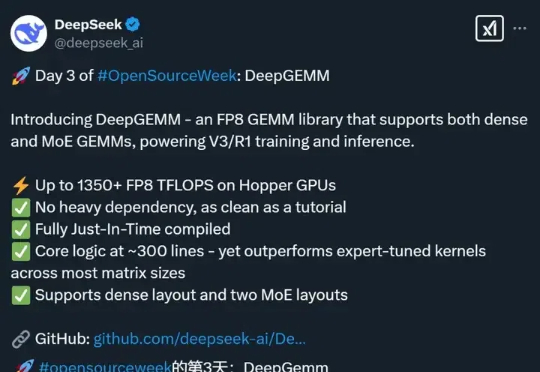
DeepSeek 的开源周已经进行到了第三天(前两天报道见文末「相关阅读」)。今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。