
不换GPU,性能飙升2.8倍!英伟达用软件暴打摩尔定律
不换GPU,性能飙升2.8倍!英伟达用软件暴打摩尔定律MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。
来自主题: AI技术研报
9276 点击 2026-04-28 10:09
 搜索
搜索
MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。

阿里前几天开源的Qwen3.6-35B-A3B,让这次讨论不再只是一次普通的新旧模型对比。它一边要面对谷歌Gemma4-26B-A4B的外部竞争,一边又必须回答一个更麻烦的问题:相较于 Qwen3.5-35B-A3B,它到底是升级,还是修补?更现实的是,很多人现在真正跑着的,其实是Qwen3.5-27B,那么这条新的35B-A3B路线,到底值不值得迁过去。
作为大模型从业者或研究员的你,是否也曾为一个模型的 “长文本能力” 而兴奋,却在实际应用中发现它并没有想象中那么智能?
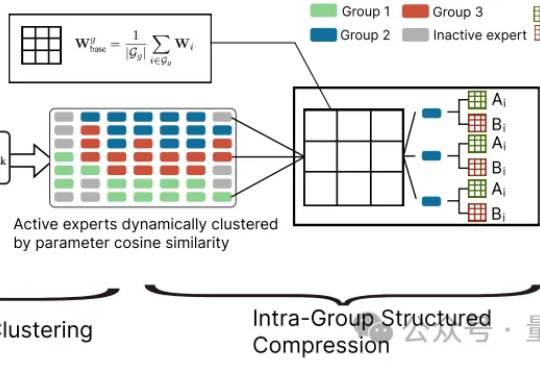
大模型参数量飙升至千亿、万亿级,却陷入“规模越大,效率越低” 困境?中科院自动化所新研究给出破局方案——首次让MoE专家告别“静态孤立”,开启动态“组队学习”。
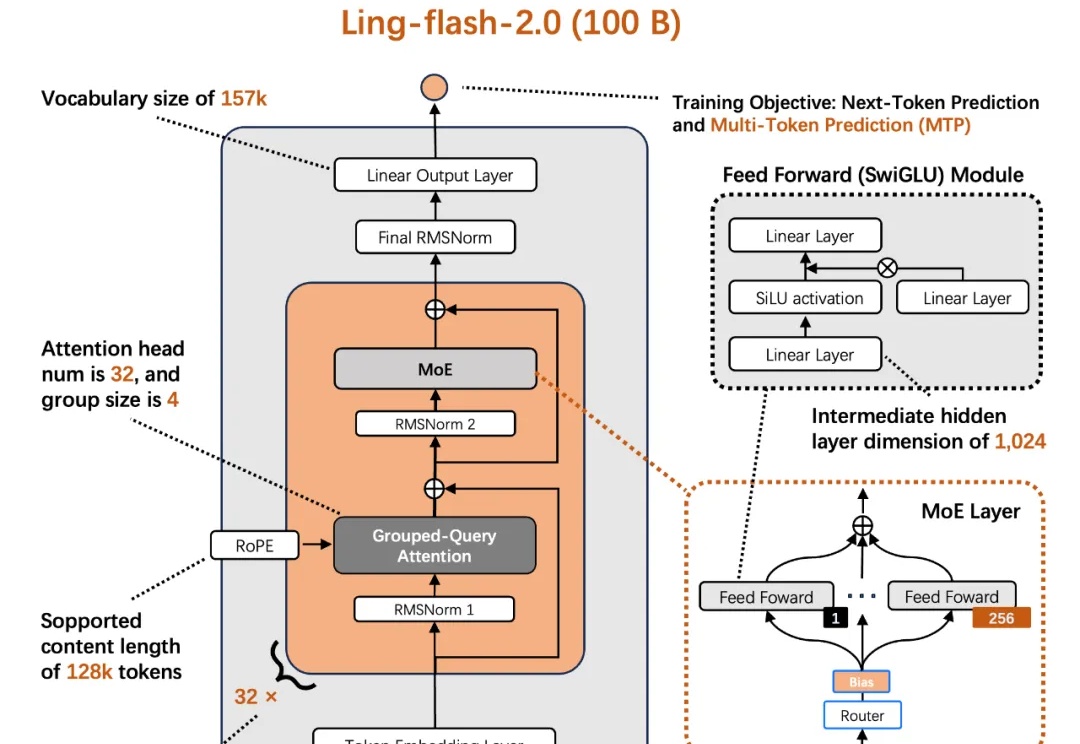
今天,蚂蚁百灵大模型团队正式开源其最新 MoE 大模型 ——Ling-flash-2.0。作为 Ling 2.0 架构系列的第三款模型,Ling-flash-2.0 以总参数 100B、激活仅 6.1B(non-embedding 激活 4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越 40B 级别 Dense 模型和更大 MoE 模型的卓越性能。

gpt5来临前夕,oai疑似发布的小模型gpt-oss 120B的架构图已经满天飞了。难得openai要open一次,自然调动了我的全部注意力机制。本来以为oai还要掏出gpt2意思意思,结果看到了一个120B moe。欸?!

超大规模MoE模型(如DeepSeek),到底该怎么推理才能做到又快又稳。现在,这个问题似乎已经有了标准答案——华为一个新项目,直接把推理超大规模MoE背后的架构、技术和代码,统统给开源了!
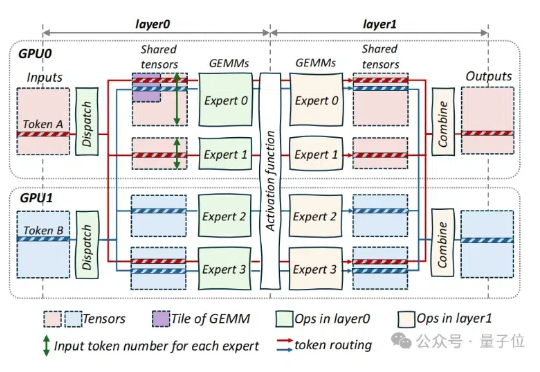
字节对MoE模型训练成本再砍一刀,成本可节省40%! 刚刚,豆包大模型团队在GitHub上开源了叫做COMET的MoE优化技术。
DeepSeek开源第二弹如期而至。这一次,他们把MoE模型内核库开源了,支持FP8专为Hopper GPU设计,低延迟超高速训练推理。
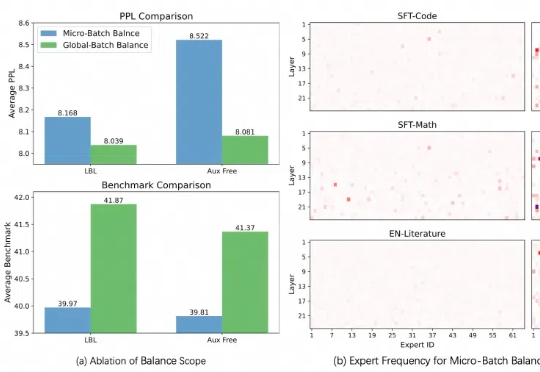
本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。