英伟达提出首个Mamba-Transformer视觉骨干网络!打破精度/吞吐瓶颈 | CVPR 2025
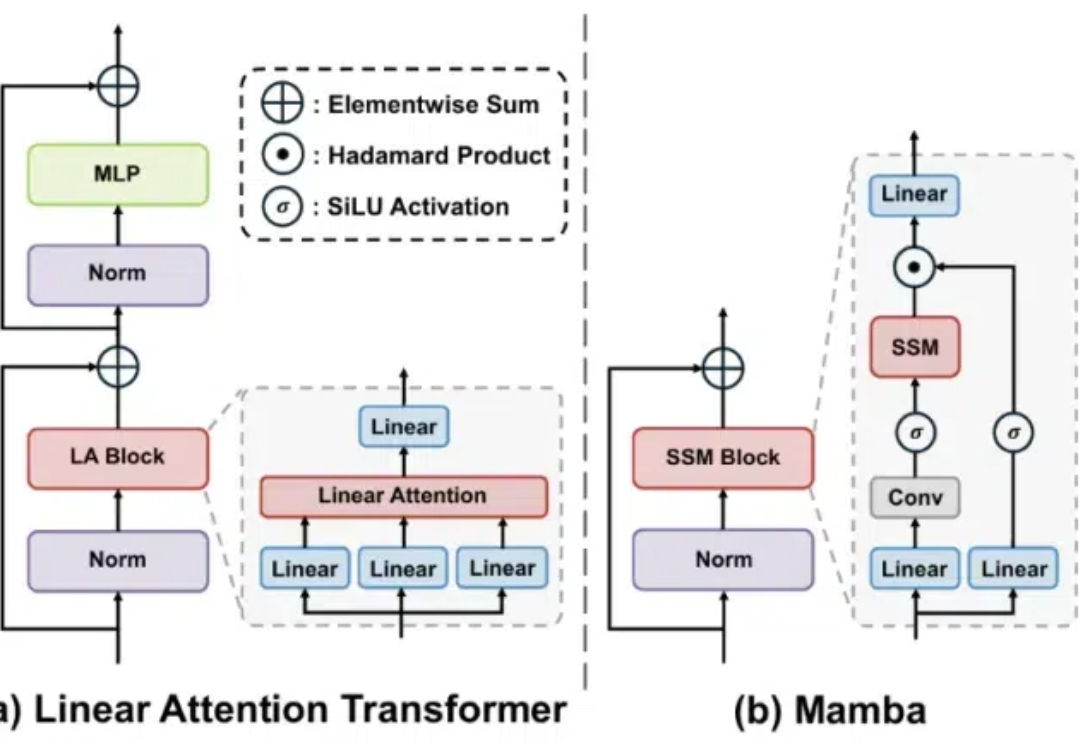
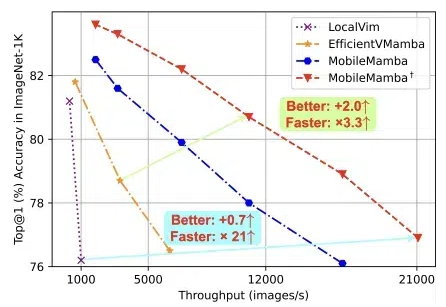
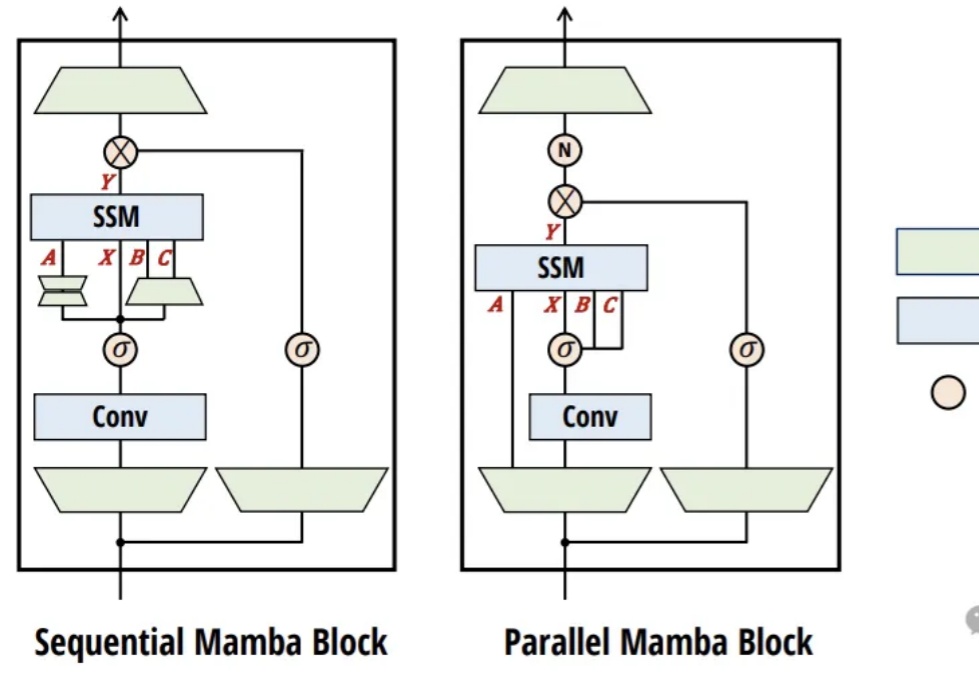
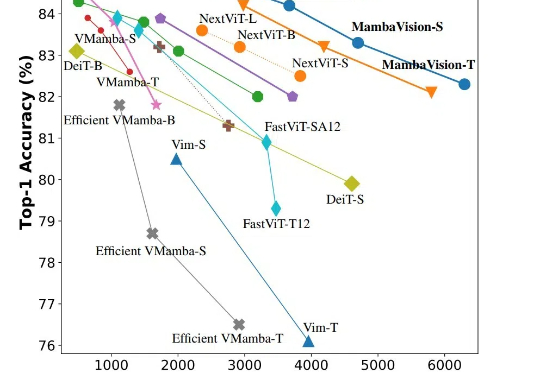
英伟达提出首个Mamba-Transformer视觉骨干网络!打破精度/吞吐瓶颈 | CVPR 2025CVPR 2025,混合新架构MambaVision来了!Mamba+Transformer混合架构专门为CV应用设计。MambaVision 在Top-1精度和图像吞吐量方面实现了新的SOTA,显著超越了基于Transformer和Mamba的模型。
来自主题: AI技术研报
10240 点击 2025-03-08 13:10