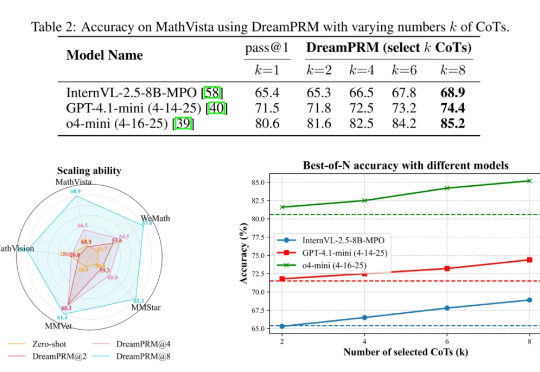
告别数据「噪音」,UCSD大模型推理新方法DreamPRM充当「信号放大器」,登顶MathVista测评榜
告别数据「噪音」,UCSD大模型推理新方法DreamPRM充当「信号放大器」,登顶MathVista测评榜使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
来自主题: AI技术研报
9123 点击 2025-07-12 11:58
 搜索
搜索
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:

大型多模态模型会做数学题吗?在UCLA等机构最新发布的MathVista基准上,即使是当前最强的GPT-4V也会感到「挫败感」。