Mistral新旗舰决战Llama 3.1!最强开源Large 2 123B,扛鼎多语言编程全能王
Mistral新旗舰决战Llama 3.1!最强开源Large 2 123B,扛鼎多语言编程全能王紧跟着Meta的重磅发布,Mistral Large 2也带着权重一起上新了,而且参数量仅为Llama 3.1 405B的三分之一。不仅在编码、数学和多语言等专业领域可与SOTA模型直接竞争,还支持单节点部署。
来自主题: AI资讯
10723 点击 2024-07-25 21:50
 搜索
搜索
紧跟着Meta的重磅发布,Mistral Large 2也带着权重一起上新了,而且参数量仅为Llama 3.1 405B的三分之一。不仅在编码、数学和多语言等专业领域可与SOTA模型直接竞争,还支持单节点部署。

AI 竞赛正以前所未有的速度加速,继 Meta 昨天推出其新的开源 Llama 3.1 模型之后,法国 AI 初创公司 Mistral AI 也加入了竞争。

Llama 3.1 405B“最强模型”宝座还没捂热乎,就被砸场子了——

小模型时代来了?OpenAI带着GPT-4o mini首次入局小模型战场,Mistral AI、HuggingFace本周接连发布了小模型。如今,苹果也发布了70亿参数小模型DCLM,性能碾压Mistral-7B。

小模型成趋势?

GPT-4o mini头把交椅还未坐热,Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。

AI经过多轮“自我提升”,能力不增反降?
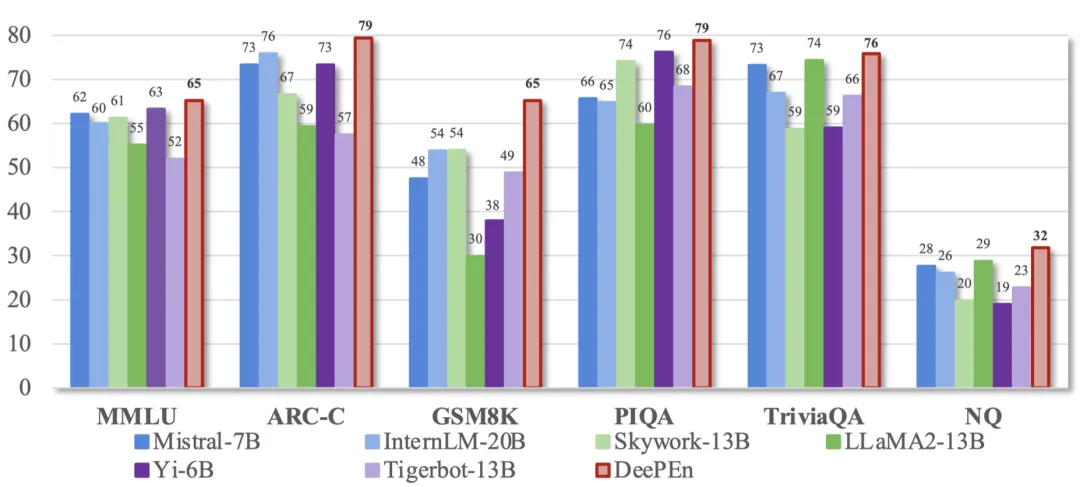
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。
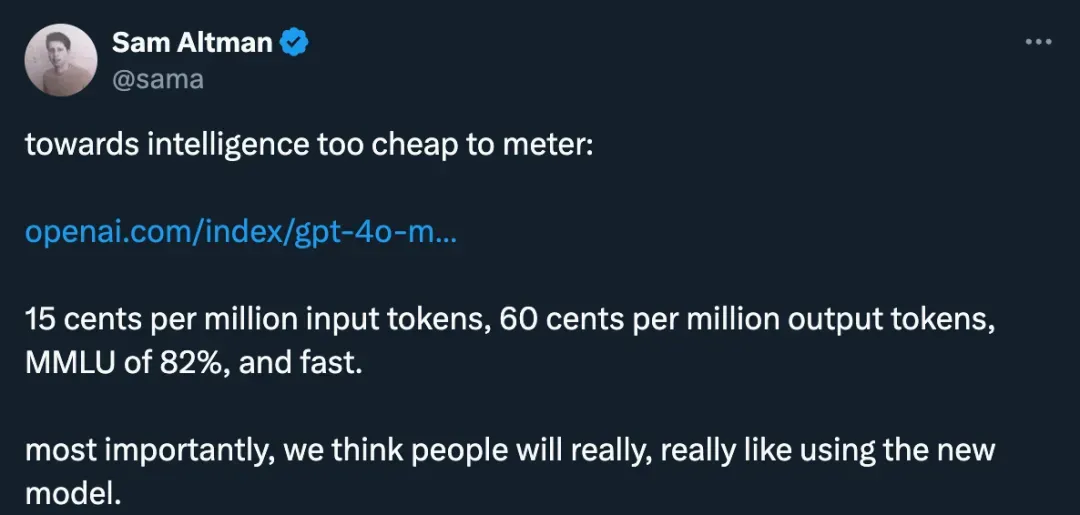
小模型,正在成为 AI 巨头的新战场。
这几日,AI 圈又一“震惊”事件!!