
首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距
首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
来自主题: AI技术研报
9140 点击 2025-04-10 10:20
 搜索
搜索
统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。

前百度集团副总裁、小度科技CEO景鲲离职创业的GenSpark,最近从AI搜索向AI Agent转型,看来是想脱离AI搜索的竞争红海,向更智能的Agents服务领域进发,推特上很多网友评价,此次新产品比较有看点。
去年 Anthropic 发布 Computer Use 的时候,引发了一次大家对 AI agent 的想象。

无人在意的角落,又一款中国AI产品在海外默默“杀疯了”。
Genspark 是啥?我们在去年 6 月就有过介绍,Genspark 是由前百度小度的 CEO 景鲲和 CTO 朱凯华创业做的 Agent 产品,去年刚开始的定位还是 Agent Search Engine,到了今天升级了不少。并且在今年三月,官宣拿到了一亿美金的 A 轮融资。
而据硅星人独家获得的消息:过去的两周 Manus 核心团队至少有两人在硅谷与风险投资机构密集接洽,硅谷头部的主流基金中至少有三家已对 Manus 团队表示了明确的投资意向,而 Manus 团队可能并不会接受其中的所有投资邀约。

Manus能撑起5亿美元估值吗?今年3月初,一款名为“Manus”的通用AI agent产品发布之后爆火。到了3月底,Manus的母公司Butterfly Effec被爆正寻求新一轮融资,目标估值将超过5亿美元。

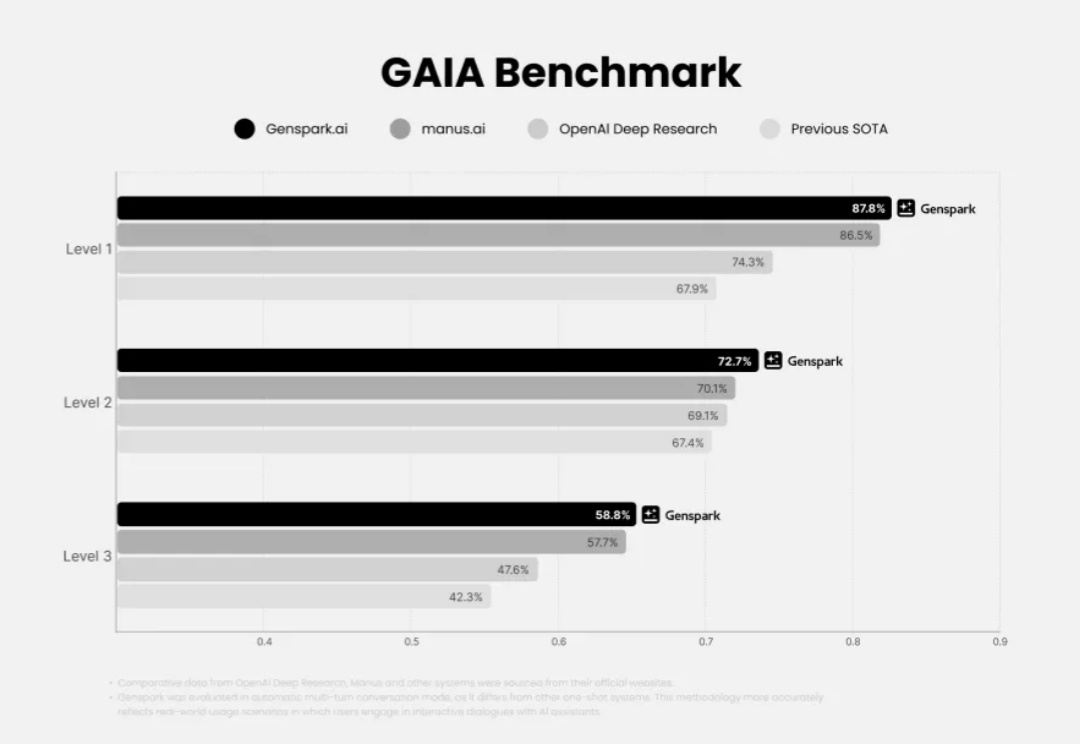
CAMEL-AI 团队在 Manus 上线后 1 天内推出的 OWL 就是其中最具代表性的一个,项目实测成绩达到开源界 GAIA 性能天花板,达到了 58.18%,超越 Huggingface 提出的 Open Deep Research 55.15% 的表现。
“首个通用智能体”Manus背后公司被曝正在硅谷寻求融资——以5亿美元估值,折合人民币37.5亿元,而距离它横空出世也不过才三周时间。从官方消息看,这几天他们确实也在硅谷面对面开用户聚会,据说是场场满员的那种。
DeepWisdom完成亿元级融资,旗下智能体产品mgx.dev以零推广首月狂揽百万美元ARR,连续四周霸榜Product Hunt全球榜首。它让普通人也能一句话做出自己的APP。