
AI顶会Poster整活大赛:我的NeurIPS论文中了ICML
AI顶会Poster整活大赛:我的NeurIPS论文中了ICMLAI 顶会越来越卷了,卷的方向你还猜不到。本周,国际机器学习大会 ICML 在韩国首尔举行。今年 ICML 的 Poster 环节,除了那些极具创新性的论文,也堪称大型学术行为艺术现场。
来自主题: AI资讯
9590 点击 2026-07-12 10:49
 搜索
搜索
AI 顶会越来越卷了,卷的方向你还猜不到。本周,国际机器学习大会 ICML 在韩国首尔举行。今年 ICML 的 Poster 环节,除了那些极具创新性的论文,也堪称大型学术行为艺术现场。
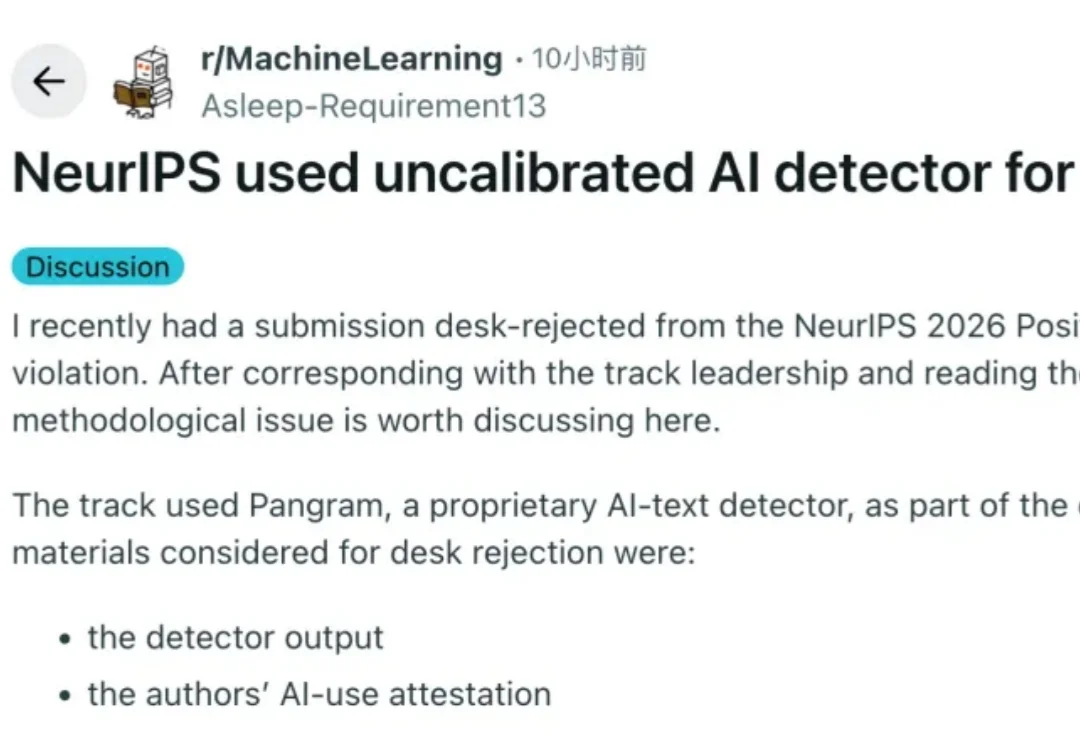
NeurIPS 2026 正在用 AI 检测器来判定「论文投稿是否使用 AI」,并作为拒稿的重要依据。

LiberAI已于近期连续完成种子轮、天使轮及天使+轮融资,累计金额数亿元人民币,投资方包括真格基金、红杉中国、美团龙珠、顺为资本等一线机构。公司成立于2025年12月,CEO刘松铭是清华特等奖学金获得者,师从清华大学朱军教授,在ICML、NeurIPS等顶会发表多篇一作论文。

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。

就在刚刚,NeurIPS在X上公开道歉,并表明: 我们已经更新了手册,与ACM、IEEE以及其他国际会议和往届NeurIPS的投稿规则保持一致。与往年一样,NeurIPS欢迎所有符合合规要求的机构和个人提交论文。

中国是NeurIPS最大的「粮仓」,却被新规一刀切断。CCF回应只有一句话:全体中国计算机领域科学家拒绝为其服务!更狠的还在后面:如不纠正错误,直接移出CCF推荐目录。

NeurIPS 不再让华为等机构投稿了?这个消息确实出自 NeurIPS 官方文件。在本届大会征稿通知的页面,藏着一个「MainTrackHandbook」的链接:打开链接,就能看到大会关于今年投稿的一些说明。

用强化学习微调扩散模型,还有更好的办法吗?

较真还得是程序员。

近日,在全球人工智能领域最具影响力的顶级学术会议 NeurIPS(神经信息处理系统大会)上, 清华大学和蚂蚁数科联合提出了一种名为 Dual-Flow 的新型对抗攻击生成框架。