
老黄「开源协议」就剩一家没签,是谁啊好难猜啊
老黄「开源协议」就剩一家没签,是谁啊好难猜啊您猜怎么着? 除了Anthropic外,几乎所有人都签了老黄的开源倡议书,包括OpenAI。
来自主题: AI资讯
8878 点击 2026-07-27 16:36
 搜索
搜索
您猜怎么着? 除了Anthropic外,几乎所有人都签了老黄的开源倡议书,包括OpenAI。

全网刷屏!11家公司的面试,57场正式面试,46个招募电话,6年博士生涯的Alisa Liu,即将加入OpenAI。这份干货满满的黄金笔记,已经在全网疯转了。

你敢信吗,OpenAI的研究人员只是因为在办公室测试了一下新模型,结果公司就要面临1亿美元的赔偿。

GPT-6和Fable 5.1,已经准备就位,很可能8月上线。据悉,本周奥特曼已经突降华盛顿,展示了OpenAI有史以来的最强大模型——GPT-6。据外媒Axios爆料,GPT-6 已经具备了进行原创科学研究的能力,并在内部测试中通过不休不眠的智能体集群(Agent Swarms),展现出危险的长程规划与自主渗透能力。
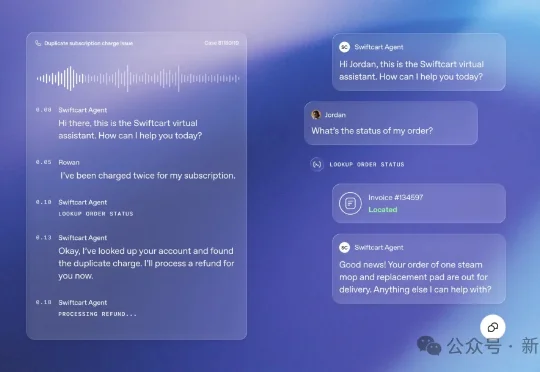
AI 客服在最近两年被认为是 Agent 商业化落地的为数不多的最佳场景之一,借助 RAG 技术,成本远低于人工客服,也让我们过上了被迫绞尽脑汁「转人工」的生活。

随着 Google DeepMind、OpenAI、Anthropic 等科技巨头相继进入生命科学领域,AI for Bio 的竞争也在发生变化:行业关注的问题,已经不再只是模型能不能回答生命科学问题,而是模型能不能真正进入科研流程,把实验做出来。

一个前沿模型,被要求随机生成一个奇数。

奇点已至!

近日,Meta 首席 AI 官、被称为公司“最高薪员工”的 Alexandr Wang,因一句简单却极具挑衅意味的话引起热议:“gemini who?(Gemini,谁啊?)”这场口水战的背后,其实是一场 AI 巨头之间的公开较量——Meta 最新模型 Muse Spark 1.1 在一份模型排行榜中超过了谷歌刚发布的 Gemini 3.6 Flash
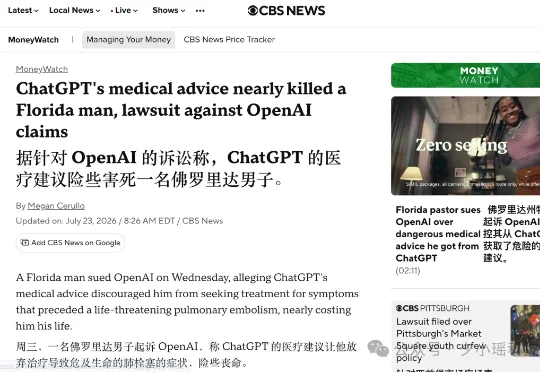
7月22日,美国佛罗里达州的牧师 Scott Winters,在旧金山把 OpenAI 和它的 CEO Sam Altman 告了。Winters 称自己在 2025 年夏天身体开始不对劲,症状持续有六个星期,这期间他没往医院跑,而是一遍遍去问 ChatGPT-4o 。可他后来才知道,那些被他反复描述的症状,其实是肺栓塞的征兆。血块堵在肺部血管里,随时会要命。