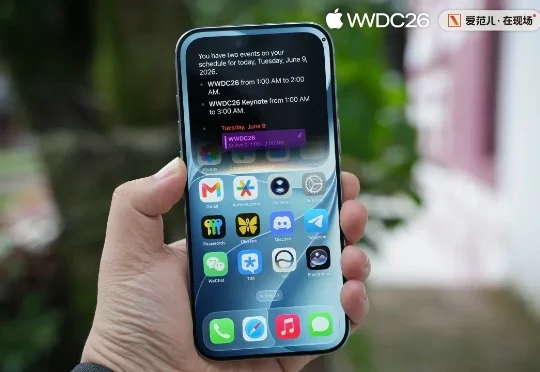
突发|苹果 AI 国行版,真的要来了
突发|苹果 AI 国行版,真的要来了刚刚,网信中国发布公告,「Apple 智能」正式通过生成式人工智能服务备案。 和苹果一起「持证上岗」的还有华为小艺 AI 大模型、OPPO AndesGPT、vivo 蓝心端侧大模型、小米澎湃 AI、三星盖乐世 AI 和努比亚豆包手机大模型,一共 7 款手机端侧大模型在 7 月 8 日集体过审。
来自主题: AI资讯
9131 点击 2026-07-15 16:40
 搜索
搜索
刚刚,网信中国发布公告,「Apple 智能」正式通过生成式人工智能服务备案。 和苹果一起「持证上岗」的还有华为小艺 AI 大模型、OPPO AndesGPT、vivo 蓝心端侧大模型、小米澎湃 AI、三星盖乐世 AI 和努比亚豆包手机大模型,一共 7 款手机端侧大模型在 7 月 8 日集体过审。
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。

2026年的AI行业,正在出现一种微妙的变化。

一家叫泛灵人工智能的团队,出了一款主打「超级办公助理」的硬件产品。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
「中国巴菲特」段永平,押注AI医疗。 数据显示,段永平Q4买入了AI医疗公司Tempus AI,新进11万股。 段永平曾一手打造小霸王、步步高,还是OPPO、vivo的幕后奠基人;之后退居幕后转向投资

硬氪获悉,AI智能运动穿戴品牌「苔源MossCode」近日完成数千万元天使轮融资,本轮由XVC和清流资本共同投资。
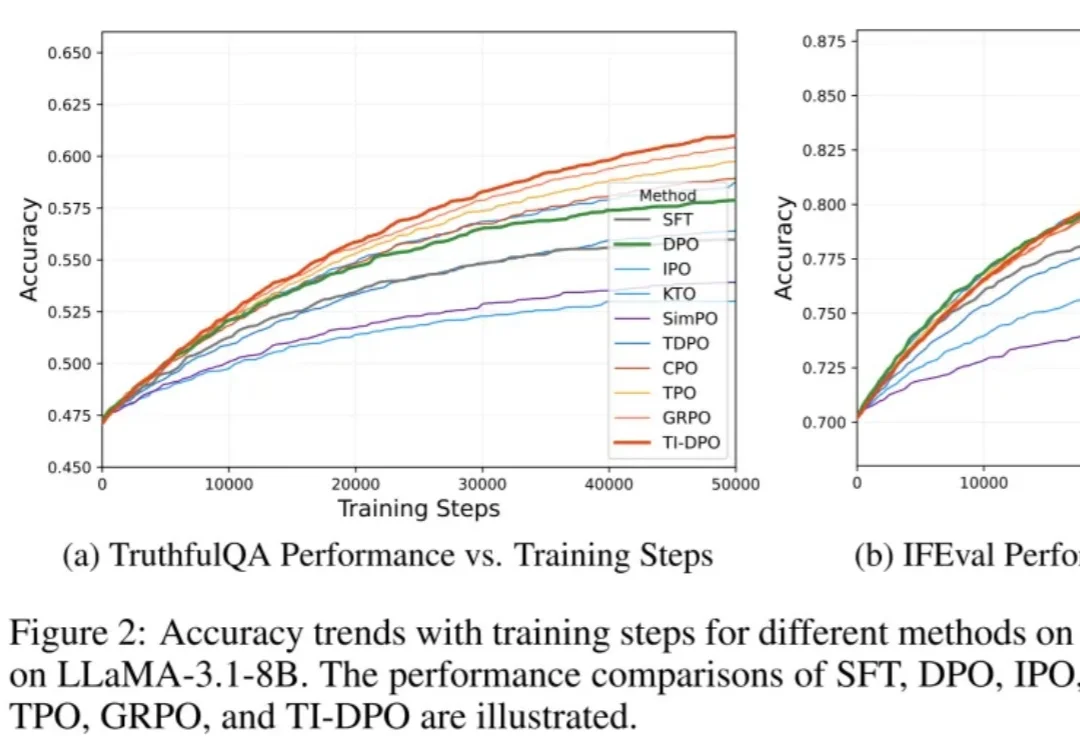
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。

全球人工智能(AI)热潮下,英国斯塔默政府在今年1月推出了雄心勃勃的“人工智能机遇行动计划”(AI Opportunities Action Plan),目标是成为“人工智能超级大国”。

AI 手机,做真正懂你的超级助理。