Z Tech | LMSYS 团队发布大规模 MoE 强化学习框架 Miles,不积跬步无以至千里
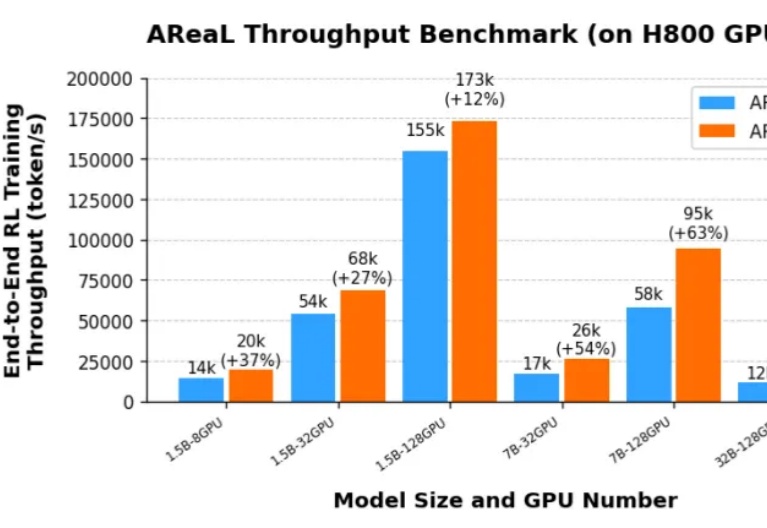
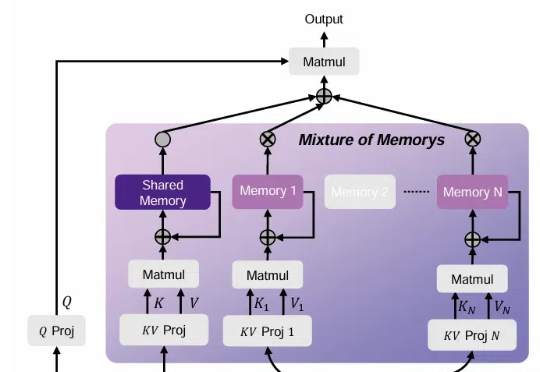
Z Tech | LMSYS 团队发布大规模 MoE 强化学习框架 Miles,不积跬步无以至千里继轻量级强化学习(RL)框架 slime 在社区中悄然流行并支持了包括 GLM-4.6 在内的大量 Post-training 流水线与 MoE 训练任务之后,LMSYS 团队正式推出 Miles——一个专为企业级大规模 MoE 训练及生产环境工作负载设计的强化学习框架。
来自主题: AI资讯
7803 点击 2025-11-20 15:26