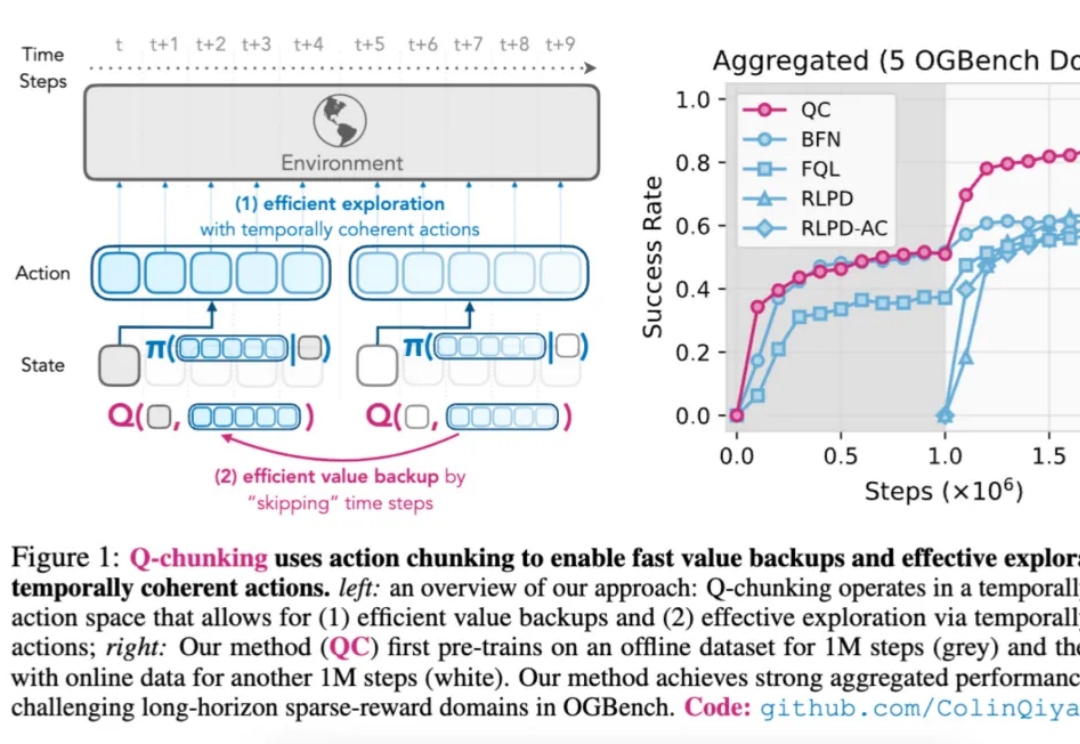
用动作分块突破RL极限,伯克利引入模仿学习,超越离线/在线SOTA 用动作分块突破RL极限,伯克利引入模仿学习,超越离线/在线SOTA 关键词: AI,模型训练,Q-chunking,强化学习 如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。 来自主题: AI技术研报 7214 点击 2025-07-14 15:16
 搜索
搜索