
突破视觉-语言-动作模型的瓶颈:QDepth-VLA让机器人拥有更精准的3D空间感知
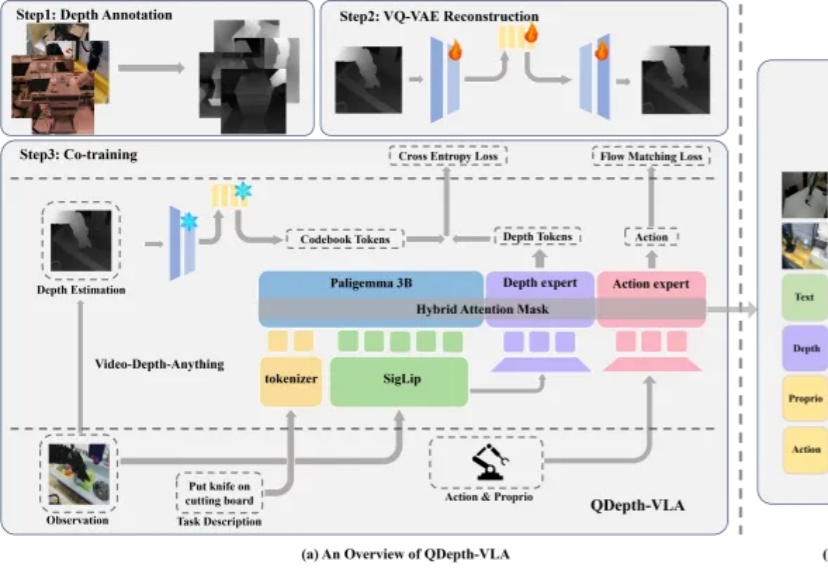
突破视觉-语言-动作模型的瓶颈:QDepth-VLA让机器人拥有更精准的3D空间感知视觉-语言-动作模型(VLA)在机器人操控领域展现出巨大潜力。通过赋予预训练视觉-语言模型(VLM)动作生成能力,机器人能够理解自然语言指令并在多样化场景中展现出强大的泛化能力。然而,这类模型在应对长时序或精细操作任务时,仍然存在性能下降的现象。
来自主题: AI技术研报
10900 点击 2025-11-27 09:48