
老黄吹的Cosmos 3,在一个北大团队做的榜单上拿了第一
老黄吹的Cosmos 3,在一个北大团队做的榜单上拿了第一刚刚过去的GTC Taipei上,最备受关注的,莫过于Cosmos 3。
来自主题: AI技术研报
8254 点击 2026-06-04 09:13
 搜索
搜索
刚刚过去的GTC Taipei上,最备受关注的,莫过于Cosmos 3。
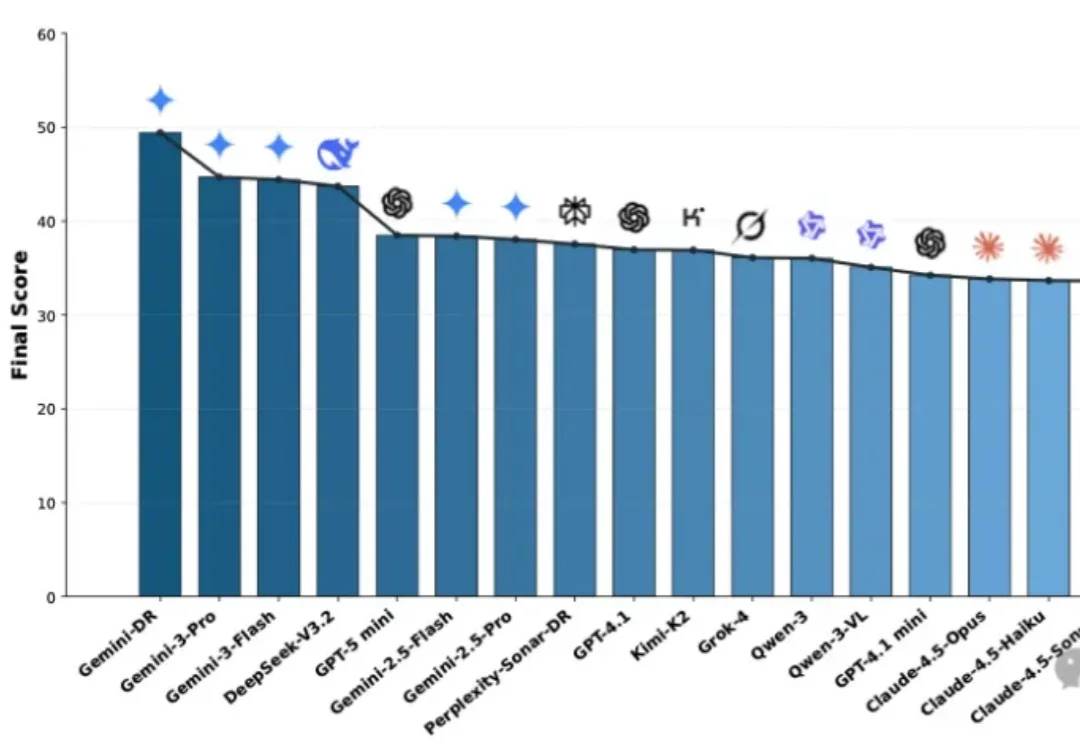
面对琳琅满目的Deep Research Agent(深度研究智能体),究竟该如何选型?本文基于OSU与Amazon最新发布的MMDR-Bench论文,为您提供一份经过严谨科学验证的“避坑指南”。结论先行:综合任务首选谷歌Gemini Deep Research,而涉及计算机科学与数据结构的硬核任务,GPT-5.2依然是专家首选。

DeepWisdom研究团队提出:视频生成模型不仅能画画,更能推理。 为了验证这一观点,团队推出了VR-Bench——这是首个通过迷宫任务评估视频模型空间推理(spatial reasoning)能力的基准测试
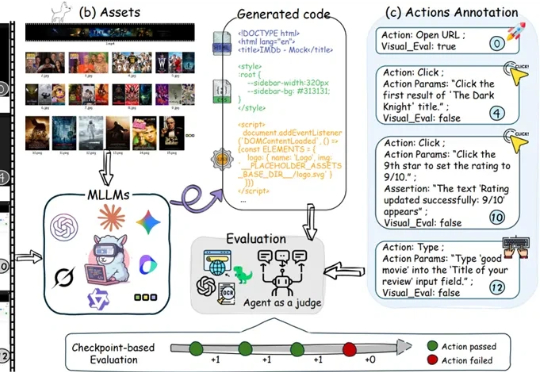
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
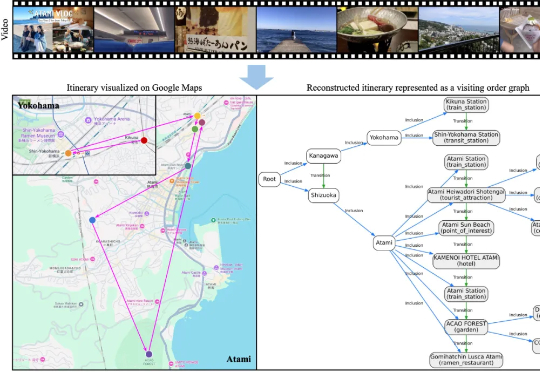
大家或许都有过这样的体验: 看完一部喜欢的动漫,总会心血来潮地想去 “圣地巡礼”;刷到别人剪辑精美的旅行 vlog,也会忍不住收藏起来,想着哪天亲自走一遍同样的路线。旅行与影像的结合,总是能勾起人们的
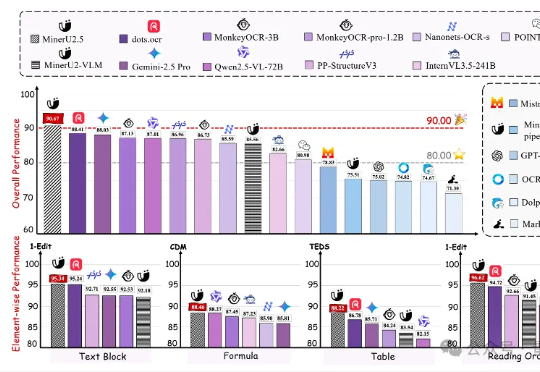
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。

视频理解的CoT推理能力,怎么评?