
新“SOTA”推理模型避战Qwen和R1?欧版OpenAI被喷麻了
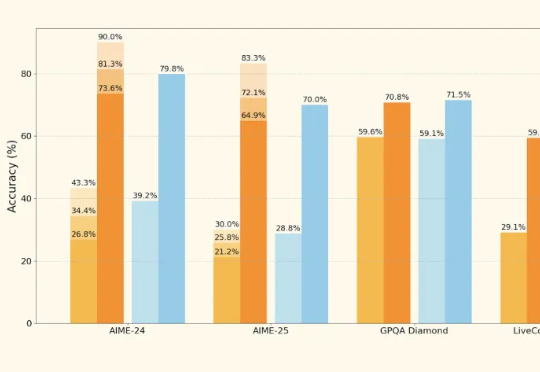
新“SOTA”推理模型避战Qwen和R1?欧版OpenAI被喷麻了“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。 然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?
来自主题: AI资讯
9669 点击 2025-06-11 14:23
“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。 然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
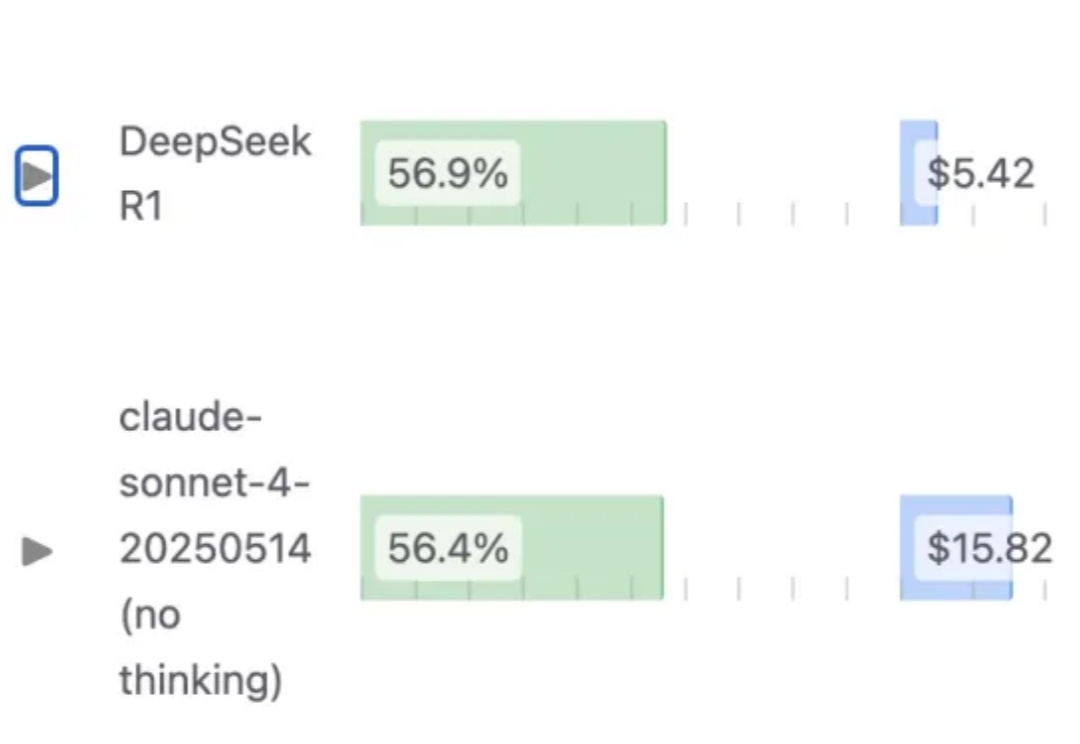
1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?

Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)

人工智能热潮使部分初创企业实现爆发式增长。但据估算,没有企业能比开发热门AI 编程助手 Cursor 的 Anysphere 增长更快。
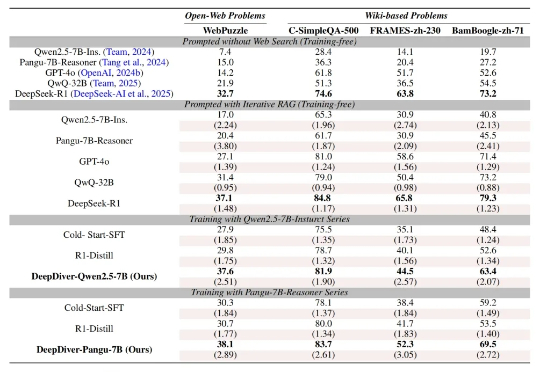
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?
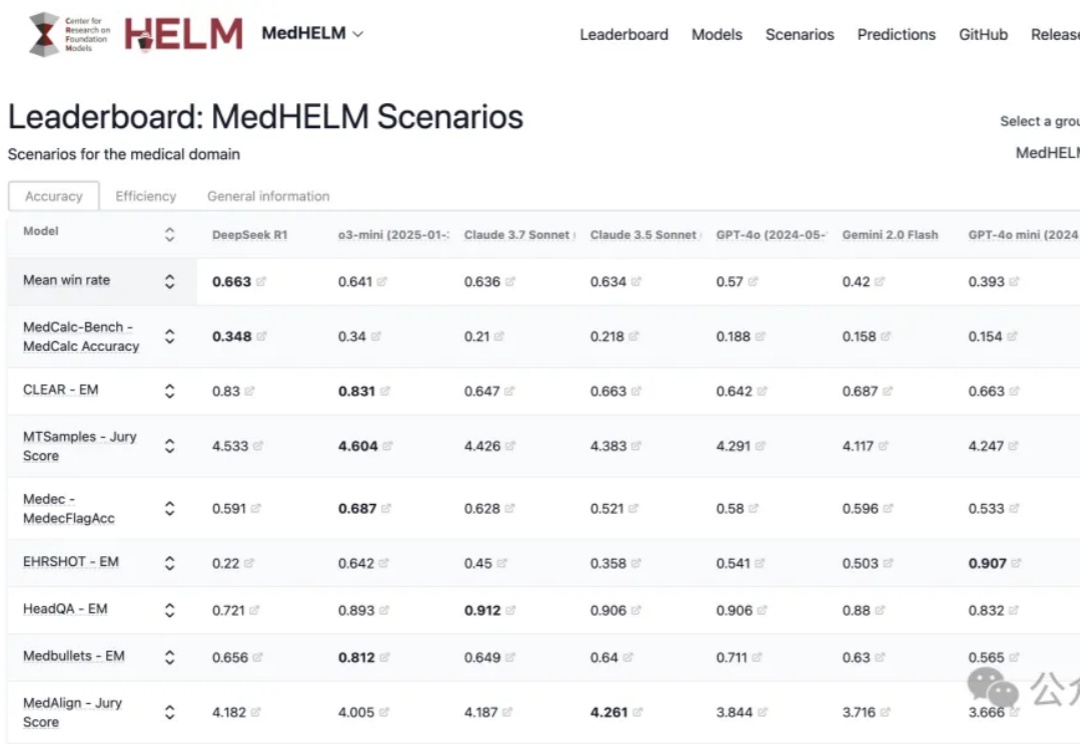
斯坦福最新大模型医疗任务全面评测,DeepSeek R1以66%胜率拿下第一!