

MiniMax正暗戳戳憋大招
MiniMax正暗戳戳憋大招MiniMax即将发布代号M+的文本推理模型,其表现将影响公司未来竞争力。面对DeepSeek R1的冲击,MiniMax采取国内C端不接入、海外接入的策略,并推出类Manus产品MiniMax Agent。公司通过品牌拆分(海螺AI更名)、纯API商业模式拓展市场,语音模型商业化效果显著,但未进入“基模五强”名单。新推理模型或成其保持行业地位的关键。
来自主题: AI资讯
9783 点击 2025-06-03 00:16
MiniMax即将发布代号M+的文本推理模型,其表现将影响公司未来竞争力。面对DeepSeek R1的冲击,MiniMax采取国内C端不接入、海外接入的策略,并推出类Manus产品MiniMax Agent。公司通过品牌拆分(海螺AI更名)、纯API商业模式拓展市场,语音模型商业化效果显著,但未进入“基模五强”名单。新推理模型或成其保持行业地位的关键。
几天前,没有预热,没有发布会,DeepSeek 低调上传了 DeepSeek R1(0528)的更新。
「知其然,亦知其所以然。」

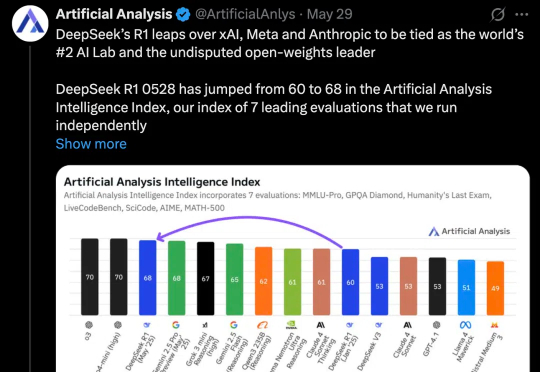
昨晚,终于等到了DeepSeek-R1-0528官宣。升级后的模型性能直逼o3和Gemini 2.5 Pro。如今,DeepSeek真正坐实了全球开源王者的称号,并成为了第二大AI实验室。
DeepSeek 猝不及防地更新了,不是 R2,而是 R1 v2。

复刻DeepSeek-R1的长思维链推理,大模型强化学习新范式RLIF成热门话题。
哈喽,大家好,我是袋鼠帝 昨天下午下班后,DeepSeek R1更新了 然而他们就只是悄悄在微信群里面发布了这个消息。
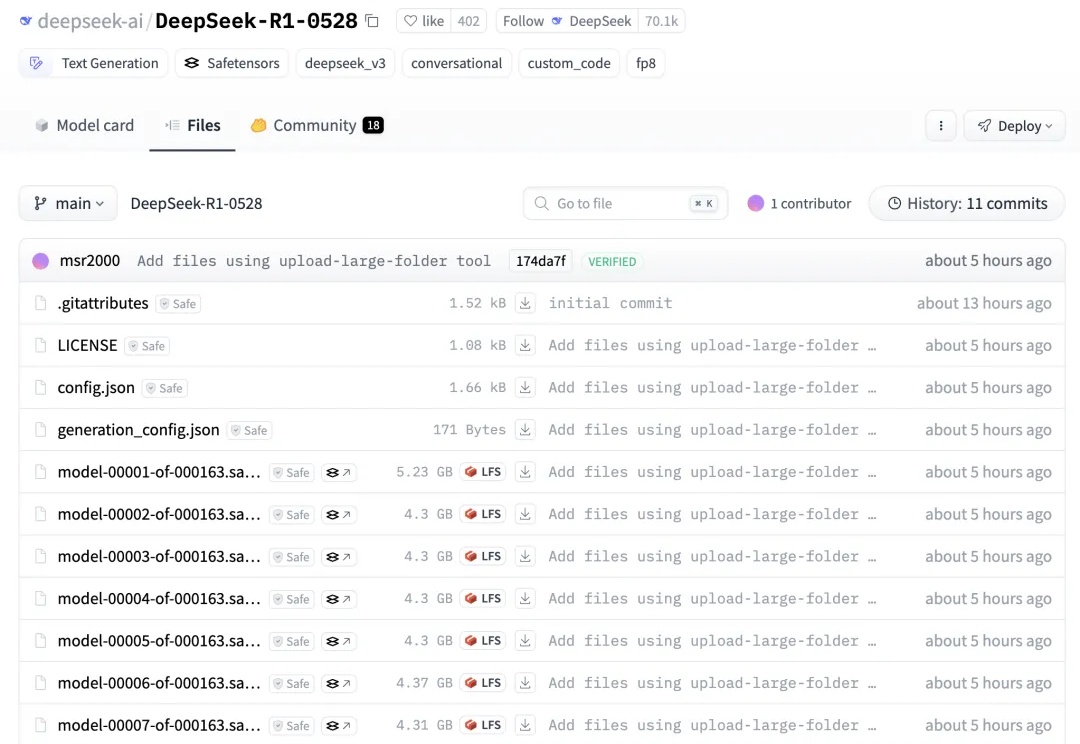
新版DeepSeek-R1重磅开源,凌晨已放出权重!此次模型性能几乎与o4-mini(Medium)相当,编程实测超越Claude 4 Sonnet。网友纷纷惊叹:开源又一次胜利了。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……
今天,我们正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。DeepSeek-R1 上线API,对用户开放思维链输出,通过设置 `model='deepseek-reasoner'` 即可调用。