
用完Claude 3.7,我感觉程序员在加速贬值
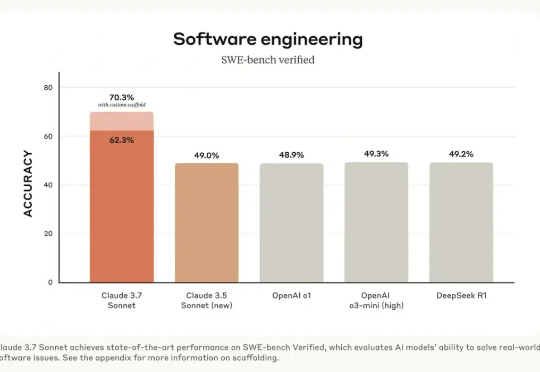
用完Claude 3.7,我感觉程序员在加速贬值昨天,Claude 3.7 Sonnet 正式发布。根据目前的各项测评,这个模型可以说是全宇宙最好的代码生成模型,超越了 DeepSeek R1 和 OpenAI 的 o3 等模型。如果你是程序员,一定要第一时间切换过去,用下这款模型。
来自主题: AI资讯
7424 点击 2025-02-27 09:54
昨天,Claude 3.7 Sonnet 正式发布。根据目前的各项测评,这个模型可以说是全宇宙最好的代码生成模型,超越了 DeepSeek R1 和 OpenAI 的 o3 等模型。如果你是程序员,一定要第一时间切换过去,用下这款模型。

即日起,北京时间每日00:30-08:30为错峰时段,API 调用价格大幅下调:DeepSeek-V3 降至原价的50%,DeepSeek-R1降至25%,在该时段调用享受更经济更流畅的服务体验。具体价格参看图2.
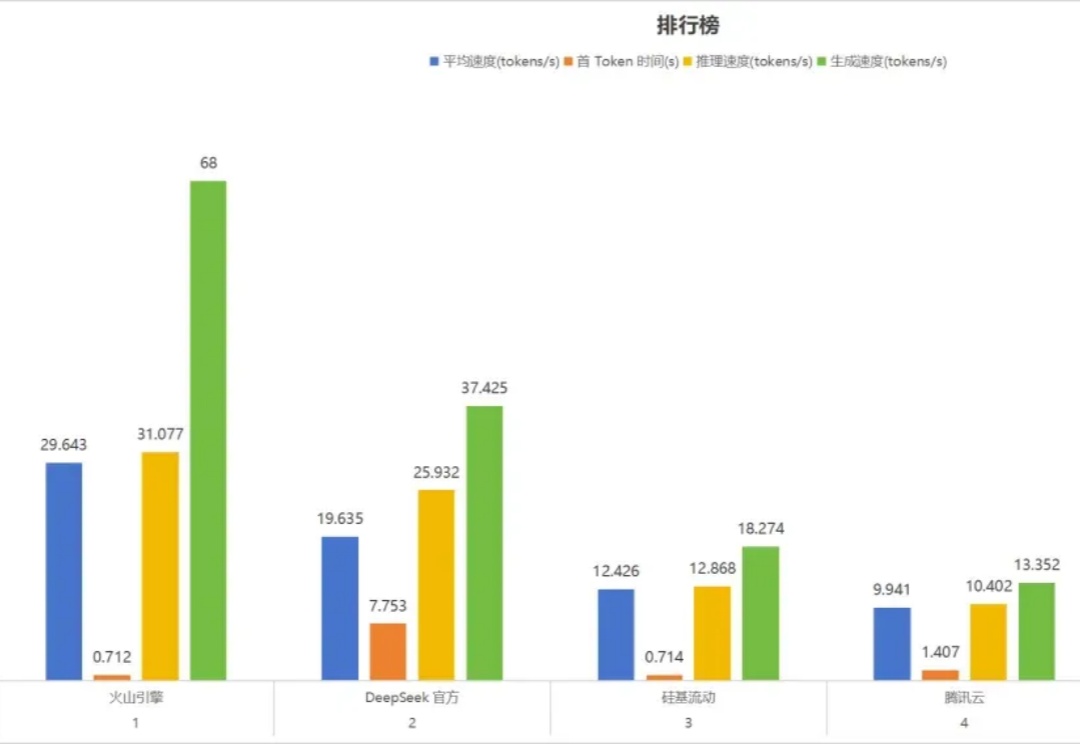
部署 DeepSeek 系列模型,尤其是推理模型 DeepSeek-R1,已经成为一股不可忽视的潮流。
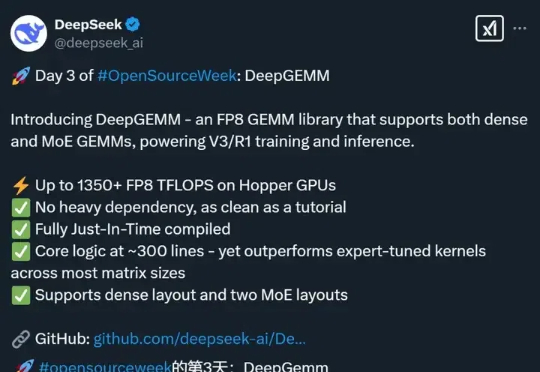
DeepSeek 的开源周已经进行到了第三天(前两天报道见文末「相关阅读」)。今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。
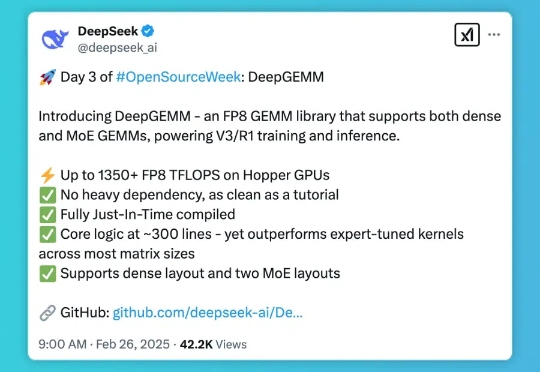
DeepSeek 开源周的第三天,带来了专为 Hopper 架构 GPU 优化的矩阵乘法库 — DeepGEMM。这一库支持标准矩阵计算和混合专家模型(MoE)计算,为 DeepSeek-V3/R1 的训练和推理提供强大支持,在 Hopper GPU 上达到 1350+FP8 TFLOPS 的高性能。

本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。

推理黑马出世,仅以5%参数量撼动AI圈。360、北大团队研发的中等量级推理模型Tiny-R1-32B-Preview正式亮相,32B参数,能够匹敌DeepSeek-R1-671B巨兽。

当地时间 2 月 25 日,Anthropic 正式发布了 Claude 3.7 Sonnet,“这是迄今为止我们最智能的模型,也是市场上首个混合推理模型。”Anthropic 官方表示。
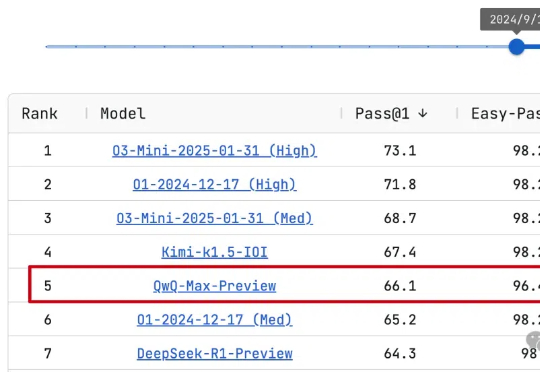
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。
知名 Chatbot 及各种 AI 工具箱产品 Monica 最近推出了国内版Monica.cn,基于 DeepSeek R1 与 V3模型,并且具备实时联网搜索与记忆能力。