
「卖铲子」也疯狂!美国「DeepSeek概念」AI初创,估值达33亿美元
「卖铲子」也疯狂!美国「DeepSeek概念」AI初创,估值达33亿美元美国AI云服务商Together AI宣布完成3.05亿美元B轮融资,估值高达33亿美元!该公司押注开源模型,提供包括DeepSeek-R1在内的200多个模型API服务,并出租GPU算力,年收入已超1亿美元。
来自主题: AI资讯
8251 点击 2025-02-21 16:35
美国AI云服务商Together AI宣布完成3.05亿美元B轮融资,估值高达33亿美元!该公司押注开源模型,提供包括DeepSeek-R1在内的200多个模型API服务,并出租GPU算力,年收入已超1亿美元。
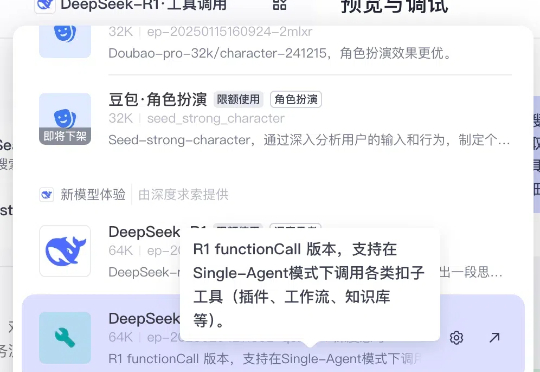
众所周知,目前 DeepSeek R1 有一个很大的痛点是不支持 Function Call 的。GitHub 上有许多开发者都表达了这一诉求。
DeepSeek-R1这样的推理模型有着强大的深度思考能力,但也有着一些不同于通用模型的特点与用法,比如不支持函数调用,不支持结构化输出,o1甚至不支持系统提示(System Prompt)等。尽管这和它们的使用场景有关,但有时也会带来不便。今天我们就来说说结构化输出这个常见的问题。

嘿,各位开发小伙伴,今天要给大家安利一个全新的开源项目 ——VLM-R1!它将 DeepSeek 的 R1 方法从纯文本领域成功迁移到了视觉语言领域,这意味着打开了对于多模态领域的想象空间!
近两个月,AI圈像开了倍速一样,可以说是卷疯了......
仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。
全网首发!DeepSeek V3/R1满血版低成本监督微调秘籍来了,让高达6710亿参数AI巨兽释放最强性能。
这个AI领域千亿级市场,将辐射千家万户。 DeepSeek-R1横空出世,打响了大模型比拼性价比的第一枪。 Meta、OpenAI等国外头部大模型厂商纷纷复刻或变相降价。比DeepSeek-R1晚两周发布的OpenAI o3-mini模型,定价比前代模型o1-mini降低了超6成,比前代完整版的o1模型便宜超9成。

大模型混战,一边卷能力,一边卷“低价”。 DeepSeek彻底让全球都坐不住了。 昨天,马斯克携“地球上最聪明的AI”——Gork 3在直播中亮相,自称其“推理能力超越目前所有已知模型”,在推理-测试时间得分上,也好于DeepSeek R1、OpenAI o1。不久前,国民级应用微信宣布接入DeepSeek R1,正在灰度测试中,这一王炸组合被外界认为AI搜索领域要变天。

当 DeepSeek 在春节期间爆火,所有人都在猜测国内 AI 厂商将会如何跟进时,腾讯元宝上周宣布接入满血版 DeepSeek R1,APPSO 体验后彻底告别了「服务器繁忙」。而就在刚刚,腾讯元宝正式推出自研的 Hunyuan T1 快速深度思考模型,给了我们两种深度思考模型的选择,APPSO 也提前体验了这款模型,第一时间给大家送上使用指南。