
胡彦斌 vibe 了一个筛子?
胡彦斌 vibe 了一个筛子?背景是,前两天歌手胡彦斌亲手(据说用的 Trae)做了一款让我感到害怕的 App,叫做「彦火」:这里让我害怕的,不是胡彦斌老师要来抢我饭碗了……而是……(请往下看,看完你也会怕)
来自主题: AI资讯
9173 点击 2026-06-02 15:20
 搜索
搜索
背景是,前两天歌手胡彦斌亲手(据说用的 Trae)做了一款让我感到害怕的 App,叫做「彦火」:这里让我害怕的,不是胡彦斌老师要来抢我饭碗了……而是……(请往下看,看完你也会怕)
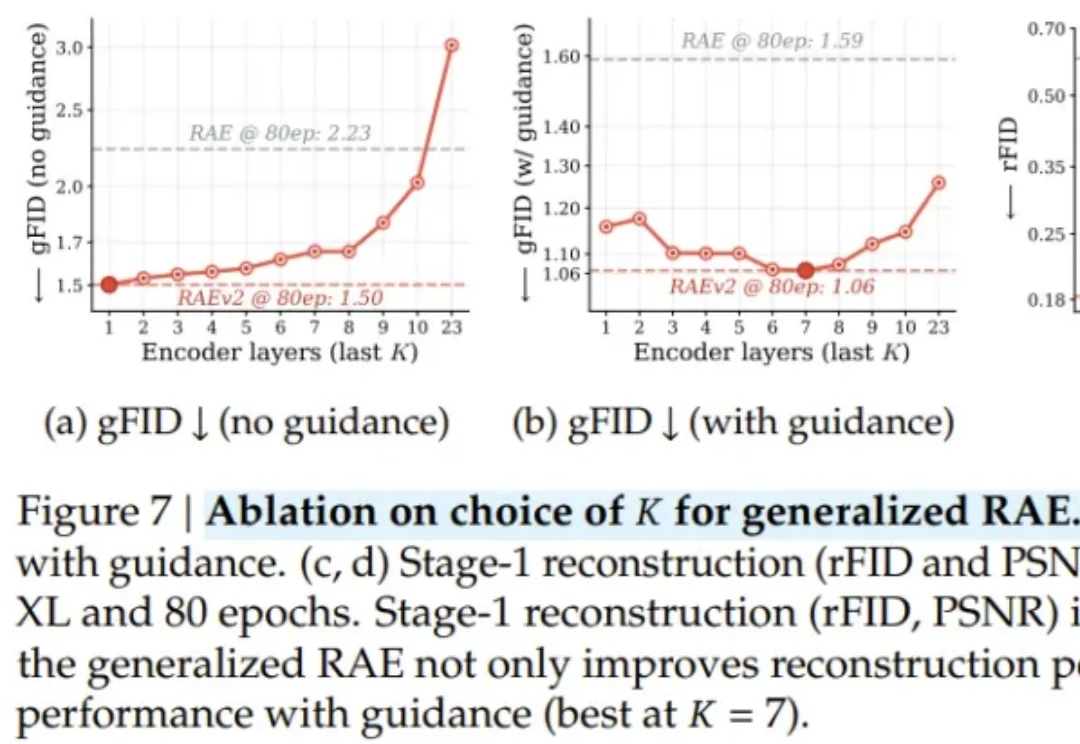
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
TRAE Editor for Unity 是一款专为 TRAE IDE 开发的,并内嵌于 Unity 编辑器的插件。它打通了 TRAE IDE 与 Unity 编辑器之间的协作链路,将 TRAE IDE 的基础功能、AI 辅助编码能力以及对 Unity 项目的深度理解融为一体,让你能够通过 Unity 编辑器直接唤起 TRAE IDE 编写代码,并便捷地回到 Unity 编辑器进行预览与调试。
TRAE SOLO 移动端正式发布,桌面端、网页端同步全量,并上线 Windows 版本桌面端;中国版三端免费开放!

我在淘宝上花了28块钱,买了一个很奇葩的东西。

Voice Working来了!TRAE SOLO把「说话」变成主力干活方式,口语自动清洗、说错自动纠正、一句话调Skill切模式。动动嘴就能指挥你的电脑干活了!

不讲 Vibe Coding,而是 Vibe Working。

字节也开始做“OpenClaw”了,但它先把战场放在了工作台上。
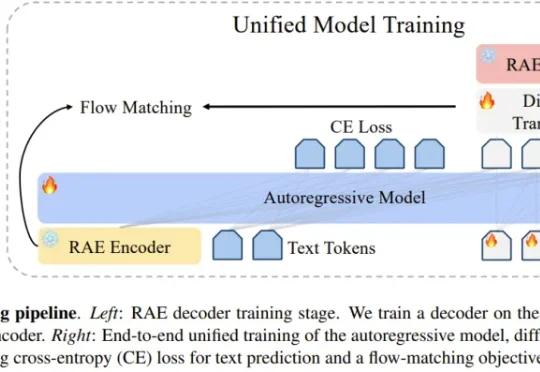
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视
比如前些天,Vercel 创始人 Guillermo Rauch 推出了所谓的「AI skill 的 npm」,让用户仅需一个简单命令 npx skills add [package],就能为自己的 AI 智能体轻松注入专业能力。