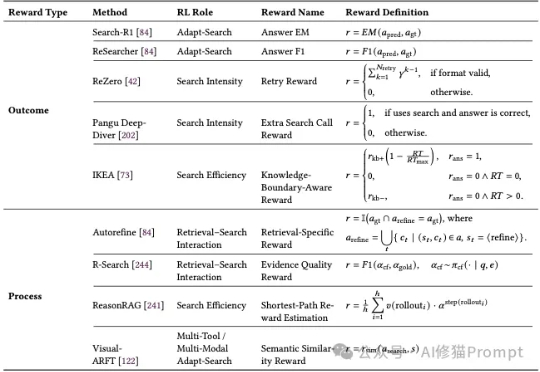
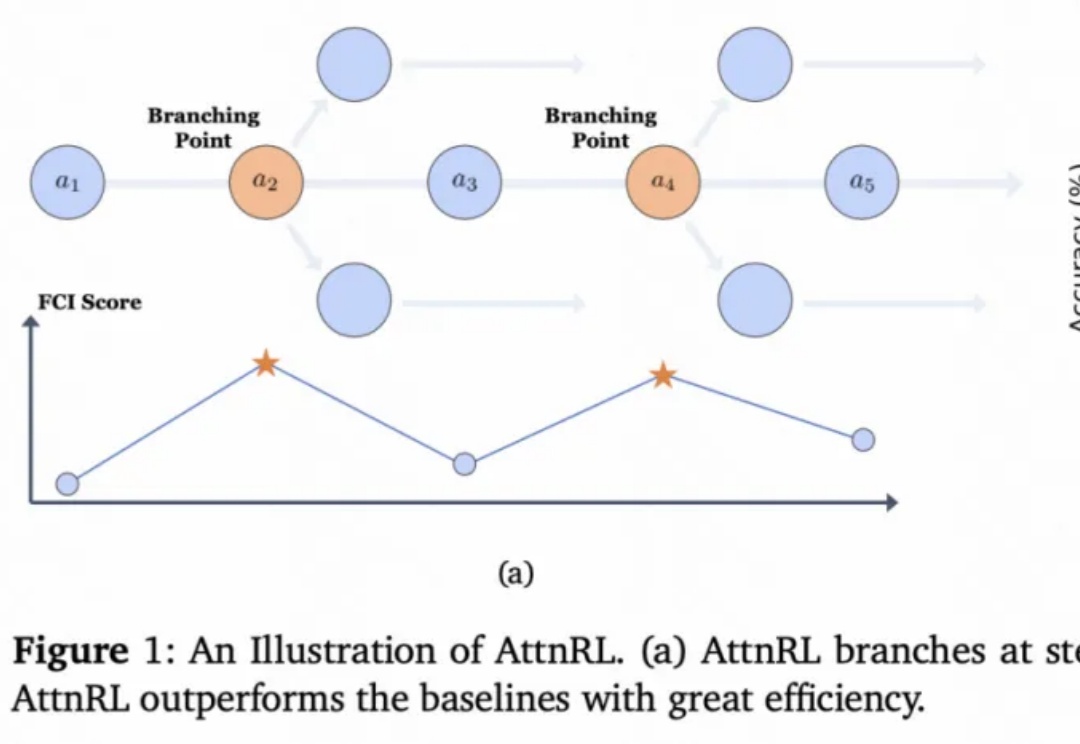
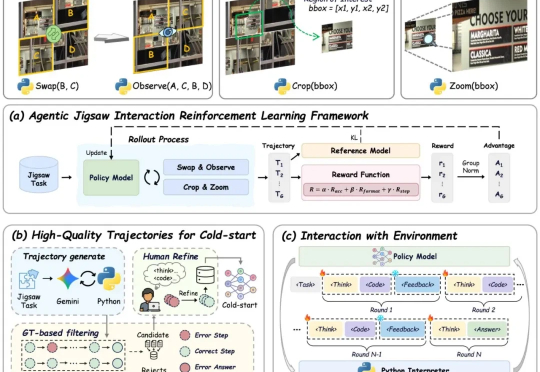
看似万能的 AI,其实比你想的更脆弱和邪恶
看似万能的 AI,其实比你想的更脆弱和邪恶十月,《纽约时报》发表了题为《The A.I. Prompt That Could End the World》(《那个可能终结世界的 AI 提示词》)的文章。作者 Stephen Witt 采访了多位业内人士:有 AI 先驱,图灵奖获奖者 Yoshua Bengio;以越狱测试著称的 Leonard Tang;以及专门研究模型欺骗的 Marius Hobbhahn。
来自主题: AI技术研报
10244 点击 2025-10-27 15:58