
刚刚,DeepSeek登上Nature封面!梁文锋带队回应质疑,R1训练真29.4万美金
刚刚,DeepSeek登上Nature封面!梁文锋带队回应质疑,R1训练真29.4万美金DeepSeek荣登Nature封面,实至名归!今年1月,梁文锋带队R1新作,开创了AI推理新范式——纯粹RL就能激发LLM无限推理能力。Nature还特发一篇评论文章,对其大加赞赏。
来自主题: AI资讯
10054 点击 2025-09-18 13:49
 搜索
搜索
DeepSeek荣登Nature封面,实至名归!今年1月,梁文锋带队R1新作,开创了AI推理新范式——纯粹RL就能激发LLM无限推理能力。Nature还特发一篇评论文章,对其大加赞赏。
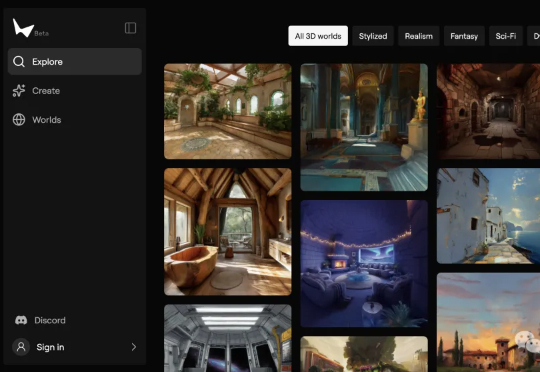
李飞飞创业公司世界模型新成果来了!只需要一个图像或者提示,就能构建出一个可以无限探索的3D世界——世界更大、风格更多样、3D几何结构更清晰,并且保持一致性、没有时间限制、没有奇怪的变形。

就在今天,斯坦福大学教授李飞飞的创业公司 World Labs 发布了新成果 —— 限量开放的测试预览版空间智能模型 Marble。「只需一张图片,就能生成持久存在的 3D 世界,比以往更宏大、更震撼!」
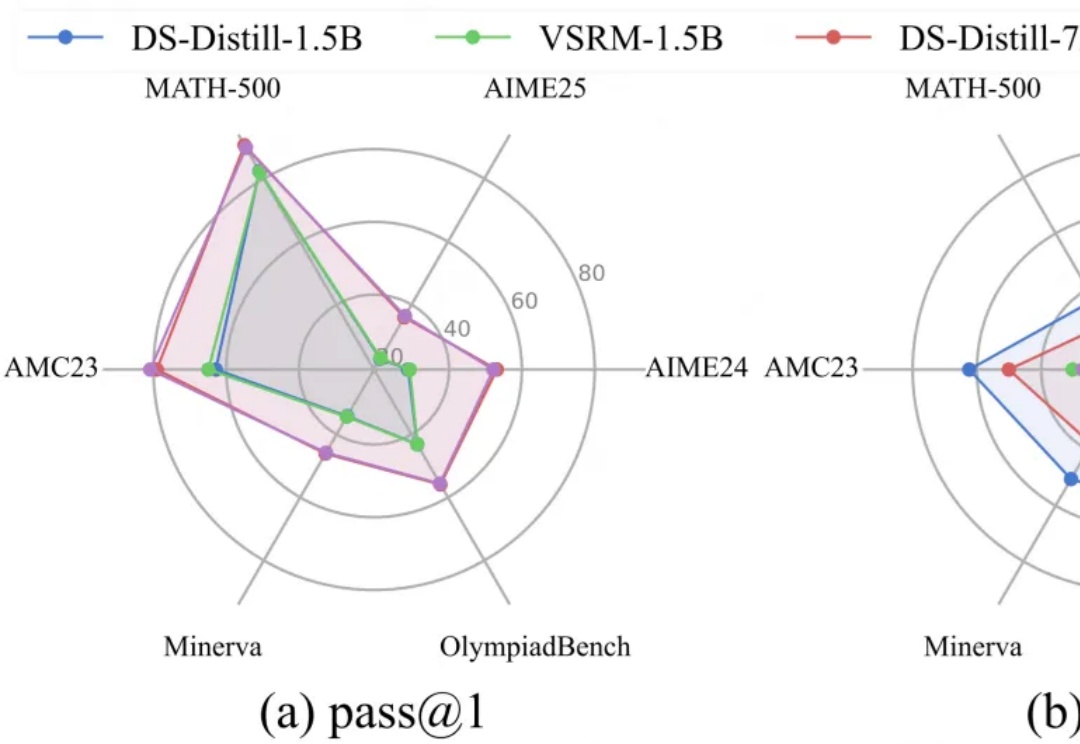
LRM通过简单却有效的RLVR范式,培养了强大的CoT推理能力,但伴随而来的冗长的输出内容,不仅显著增加推理开销,还会影响服务的吞吐量,这种消磨用户耐心的现象被称为“过度思考”问题。
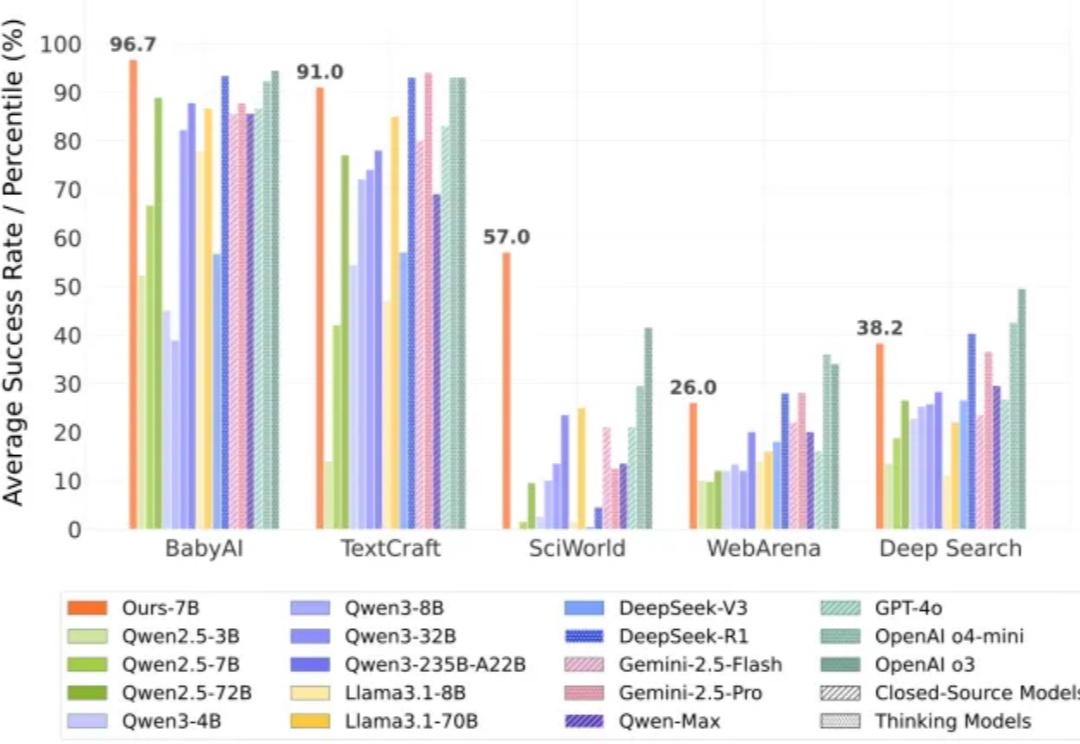
强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 曾指出,人工智能正在迈入「经验时代」—— 在这个时代,真正的智能不再仅仅依赖大量标注数据的监督学习,而是来源于在真实环境中主动探索、不断积累经验的能力。
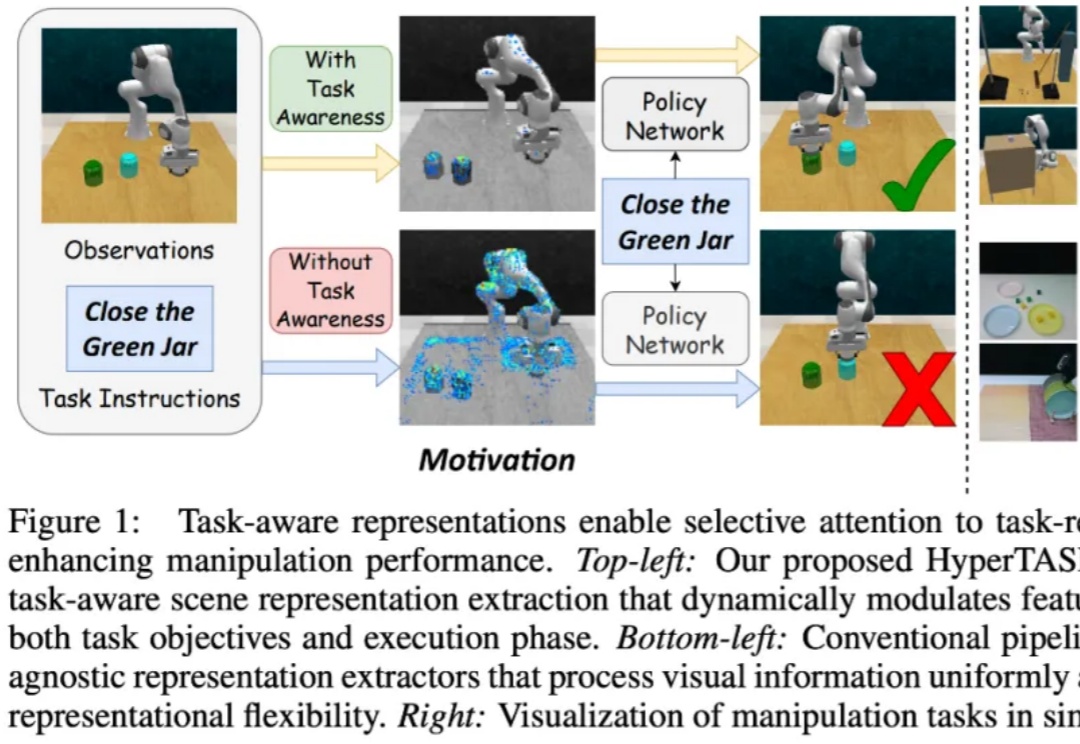
在具身智能中,策略学习通常需要依赖场景表征(scene representation)。然而,大多数现有多任务操作方法中的表征提取过程都是任务无关的(task-agnostic):

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
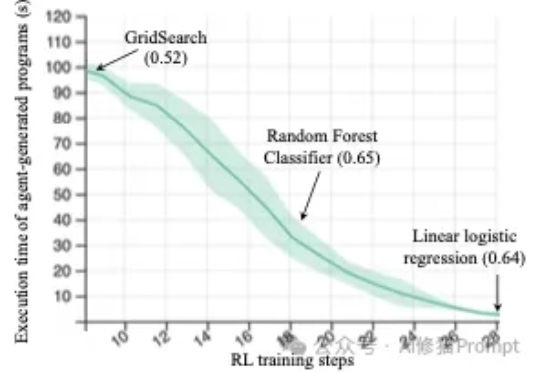
来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。
苹果自研AI搜索引擎,刚刚曝光!据长期追踪苹果资讯的彭博社记者古尔曼爆料,这家公司预计又有两个新动作: 一是在明年春季推出一款代号为“世界知识问答”(World Knowledge Answers)的AI搜索引擎,与ChatGPT和Perplexity展开直接竞争;二是当下倾向于与谷歌合作,利用谷歌模型为Siri的部分功能提供技术支持。
谷歌回归搜索老本行,这一次,它要让 AI 能像人一样「看见」网页。 这是谷歌前不久在 Gemini API 全面上线的 URL Context 功能(5 月 28 日已在 Google AI Studio 中推出),它使 Gemini 模型能够访问并处理来自 URL 的内容,包括网页、PDF 和图像。