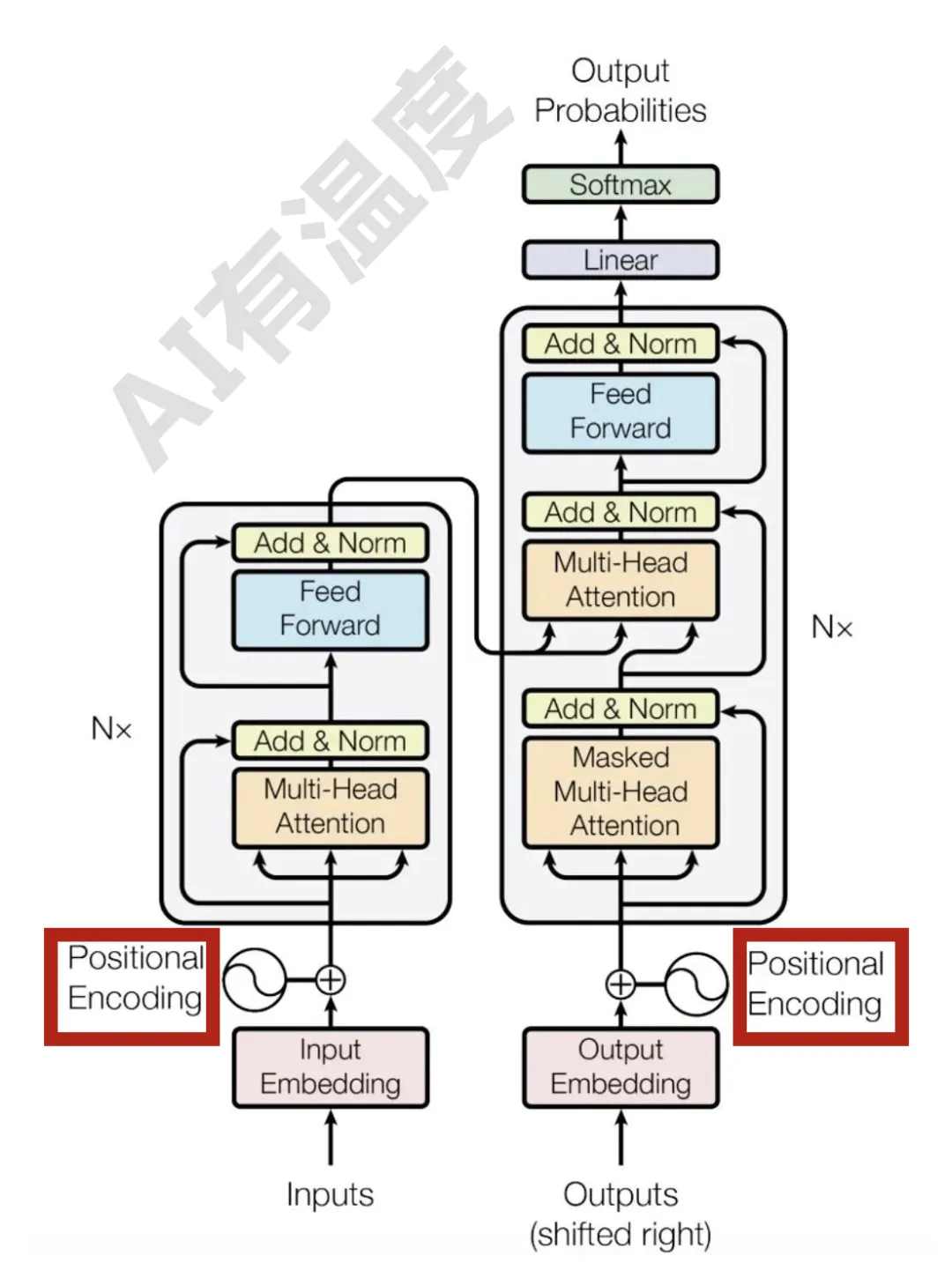
位置编码发展史:从零开始带你推导神秘的RoPE
位置编码发展史:从零开始带你推导神秘的RoPERNN每个step的隐状态都取决于上一个step的输出,这种连续的状态转移方式使得RNN天然带有位置信息。
来自主题: AI技术研报
7857 点击 2024-07-26 09:23
 搜索
搜索
RNN每个step的隐状态都取决于上一个step的输出,这种连续的状态转移方式使得RNN天然带有位置信息。

新架构,再次向Transformer发起挑战!
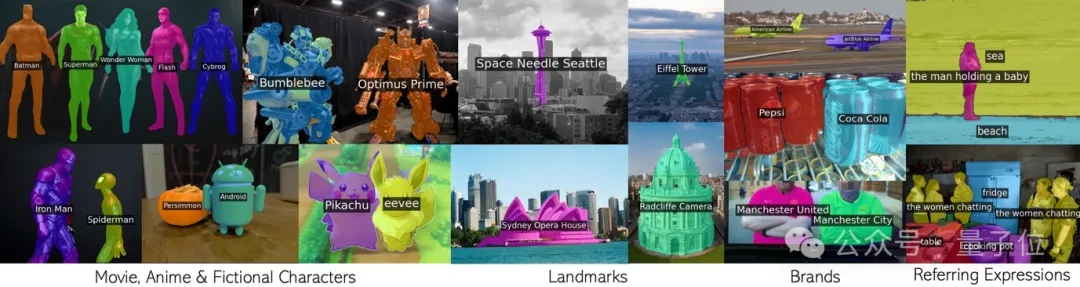
循环调用CLIP,无需额外训练就有效分割无数概念。 包括电影动漫人物,地标,品牌,和普通类别在内的任意短语。

既能像 Transformer 一样并行训练,推理时内存需求又不随 token 数线性递增,长上下文又有新思路了?

随着生成式 AI 模型掀起新一轮 AI 浪潮,越来越多的行业迎来技术变革。许多行业从业者、基础科学研究者需要快速了解 AI 领域发展现状、掌握必要的基础知识。
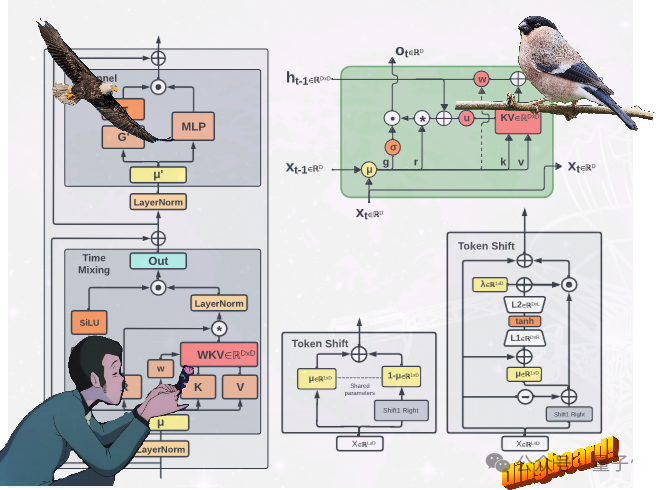
不走Transformer寻常路,魔改RNN的国产新架构RWKV,有了新进展: 提出了两种新的RWKV架构,即Eagle (RWKV-5) 和Finch(RWKV-6)。

线性RNN赢了?近日,谷歌DeepMind一口气推出两大新架构,在d基准测试中超越了Transformer。新架构不仅保证了高效的训练和推理速度,并且成功扩展到了14B。

去年 12 月,新架构 Mamba 引爆了 AI 圈,向屹立不倒的 Transformer 发起了挑战。如今,谷歌 DeepMind「Hawk 」和「Griffin 」的推出为 AI 圈提供了新的选择。

大模型内卷时代,也不断有人跳出来挑战Transformer的统治地位,RWKV最新发布的Eagle 7B模型登顶了多语言基准测试,同时成本降低了数十倍
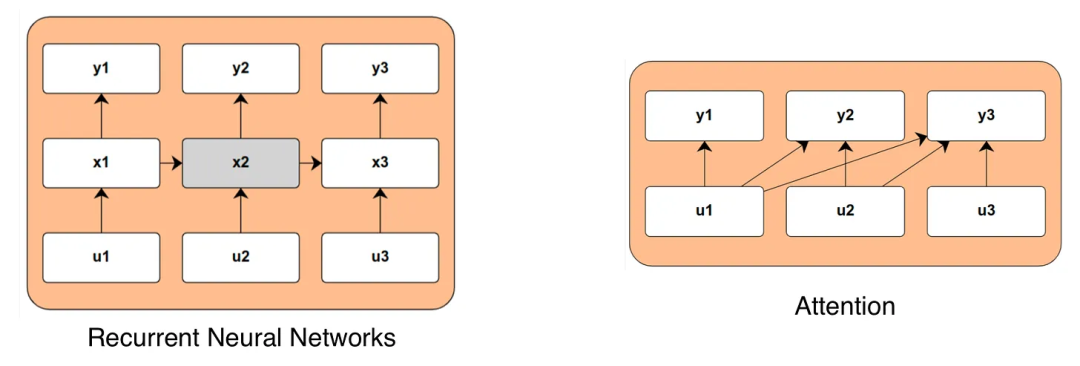
状态空间模型正在兴起,注意力是否已到尽头?