
消失的数据:一个空格如何诱发 AI Agent “删库” 惨案
消失的数据:一个空格如何诱发 AI Agent “删库” 惨案该事故目前已得到谷歌官方技术团队的确认,官方承认属于 “Systemic path-parsing failure ”“Catastrophic impact”“Have seen before”,正在紧急硬编码修复上线中(自 2 月 6 日回复起,截止目前,暂未有修复完成的正式通知)
来自主题: AI资讯
9124 点击 2026-02-13 18:52
 搜索
搜索
该事故目前已得到谷歌官方技术团队的确认,官方承认属于 “Systemic path-parsing failure ”“Catastrophic impact”“Have seen before”,正在紧急硬编码修复上线中(自 2 月 6 日回复起,截止目前,暂未有修复完成的正式通知)
AI工具越出越快,很多人越学越焦虑:怕被裁,怕落后,怕同事比自己更会用AI。一款名为Cursiv AI的教育App就盯着这股情绪下手,12个月内IAP收入超300万美金。

香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。
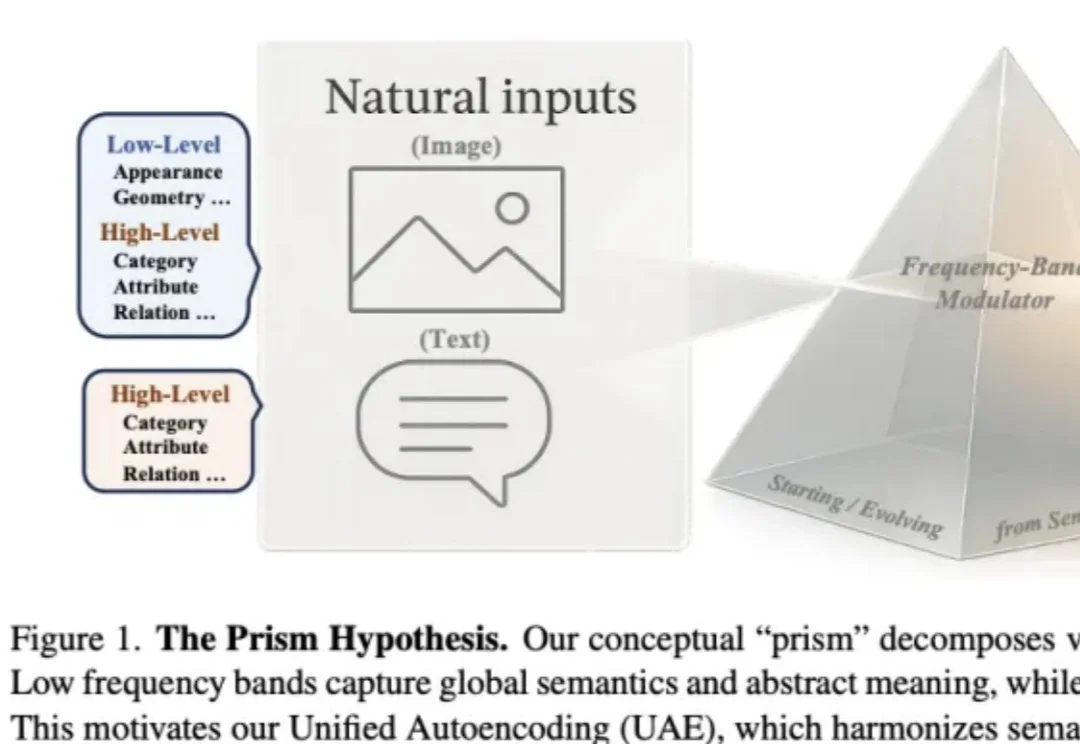
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。

今天凌晨,喜欢闷声做大事的 DeepSeek 再次发布重大技术成果,在其 GitHub 官方仓库开源了新论文与模块 Engram,论文题为 “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”, 梁文锋再次出现在合著者名单中。
我自己做内容创作这么久,一直在观察各种 AI 产品的崛起和消亡。说实话,看到 Corsif 的成功时,我的第一反应是震惊。这个应用的核心功能简单到令人难以置信,就是用一些基础的课程教人怎么写 ChatGPT 提示词

你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
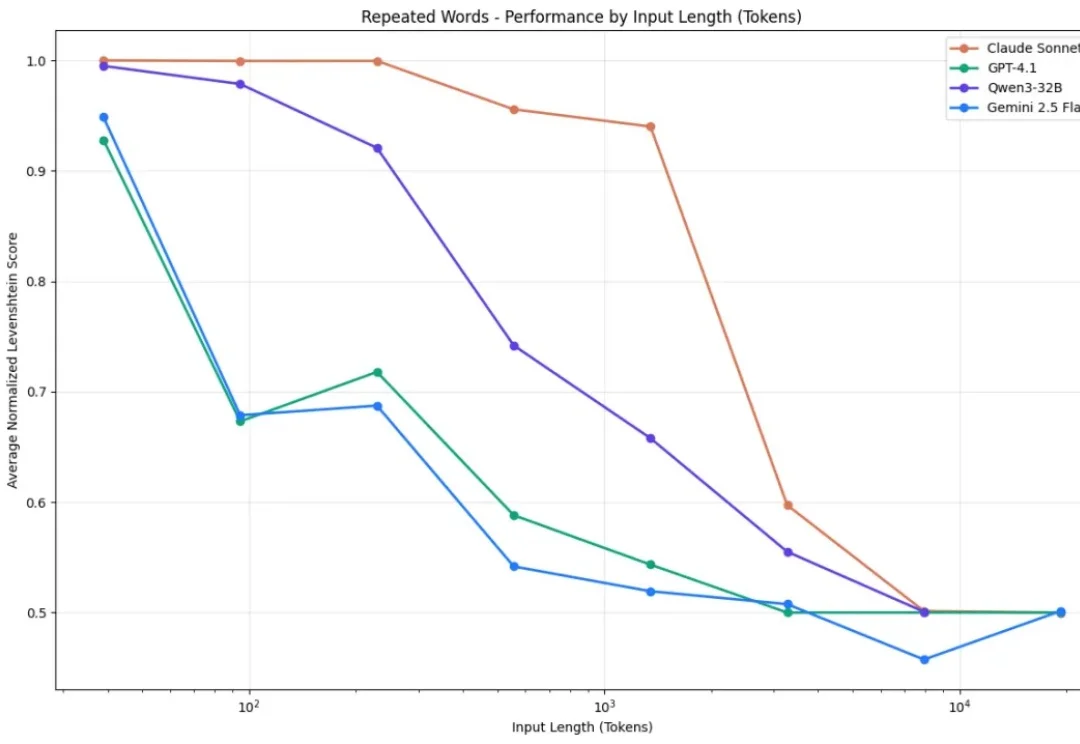
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。

破解AI胡说八道的关键,居然是给大模型砍断99.9%的连接线?

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。