
“游戏圈野蛮人”跳进AI火坑,周亚辉要“拳打Netflix、脚踢Spotify”!
“游戏圈野蛮人”跳进AI火坑,周亚辉要“拳打Netflix、脚踢Spotify”!昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。
来自主题: AI资讯
8554 点击 2026-05-02 13:36
 搜索
搜索
昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。

让静态3D模型「动起来」一直是图形学界的难题:物理模拟太慢,生成模型又不讲「物理基本法」。近日,北京大学团队提出DragMesh,通过「语义-几何解耦」范式与双四元数VAE,成功将核心生成模块的算力消耗降低至SOTA模型的1/10,同时将运动轴预测误差降低了10倍。

2025倒计时,新SOTA模型涌现没有放缓迹象。一夜之间,编程SOTA模型易主,而且上线即开源,依然来自中国大模型公司——智谱AI,GLM-4.7。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。
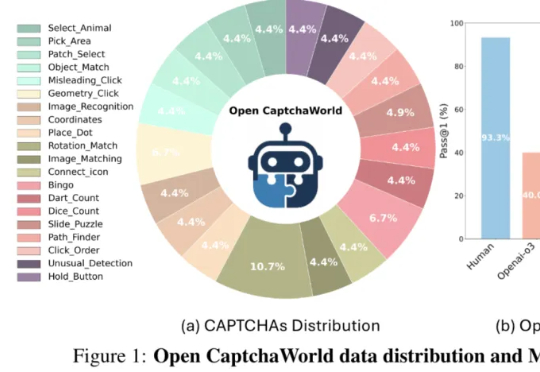
当前最强多模态Agent连验证码都解不了?

就在刚刚,智源研究员联合多所高校开放三款向量模型,以大优势登顶多项测试基准。其中,BGE-Code-v1直接击穿代码检索天花板,百万行级代码库再也不用怕了!

文本到图像(Text-to-Image, T2I)生成任务近年来取得了飞速进展,其中以扩散模型(如 Stable Diffusion、DiT 等)和自回归(AR)模型为代表的方法取得了显著成果。然而,这些主流的生成模型通常依赖于超大规模的数据集和巨大的参数量,导致计算成本高昂、落地困难,难以高效地应用于实际生产环境。

超低成本图像生成预训练方案来了——仅需8张GPU训练,就能实现近SOTA的高质量图像生成效果。

性能不输SOTA模型,计算开销却更低了——