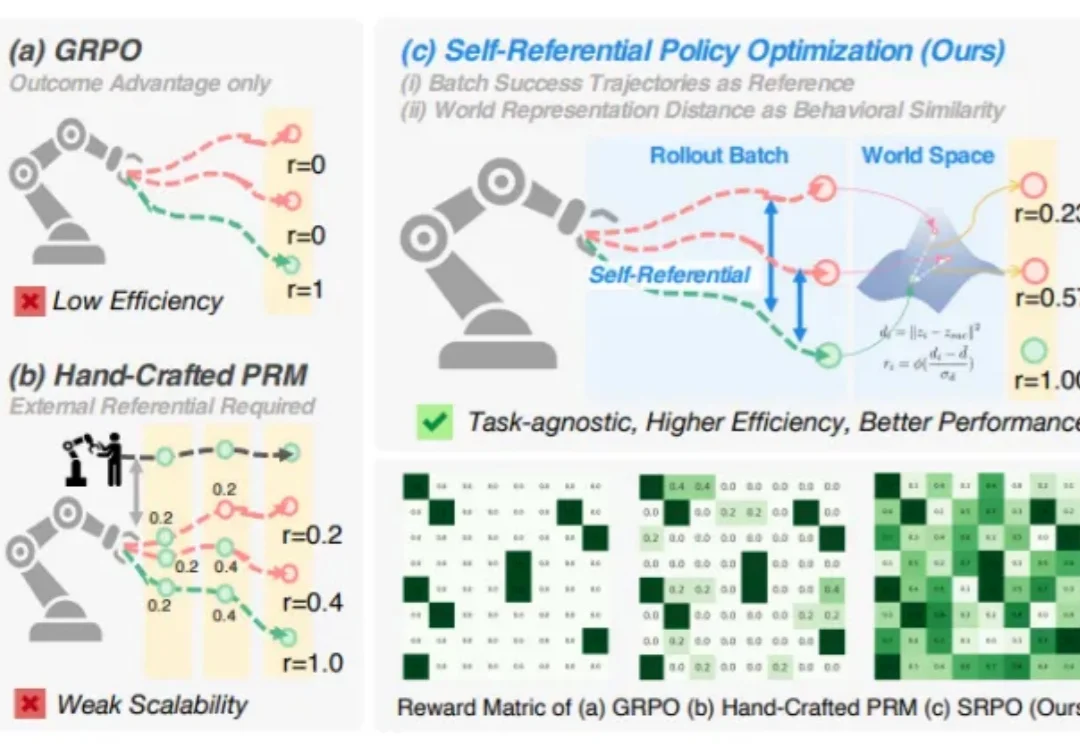
告别专家依赖,让机器人学会自我参考,仅需200步性能飙升至99.2%
告别专家依赖,让机器人学会自我参考,仅需200步性能飙升至99.2%你是否想过,机器人也能像人一样,从失败中学习,不断自我提升?
来自主题: AI技术研报
11026 点击 2025-12-11 10:08
 搜索
搜索
你是否想过,机器人也能像人一样,从失败中学习,不断自我提升?
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。