花了1000倍的token,效果可能却没有更好:AI Agent的“隐性账单”长什么样
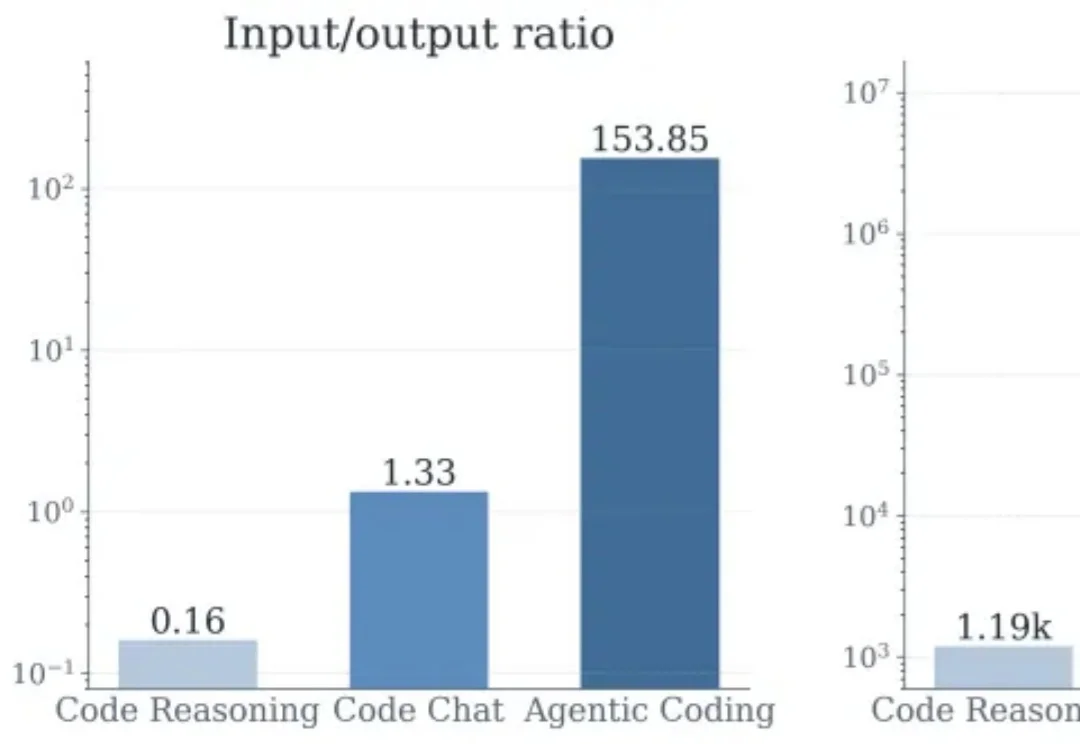
花了1000倍的token,效果可能却没有更好:AI Agent的“隐性账单”长什么样如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。
来自主题: AI技术研报
6810 点击 2026-05-19 10:00