视觉latent reasoning为什么不稳?这篇论文从特征空间找到了关键缺口
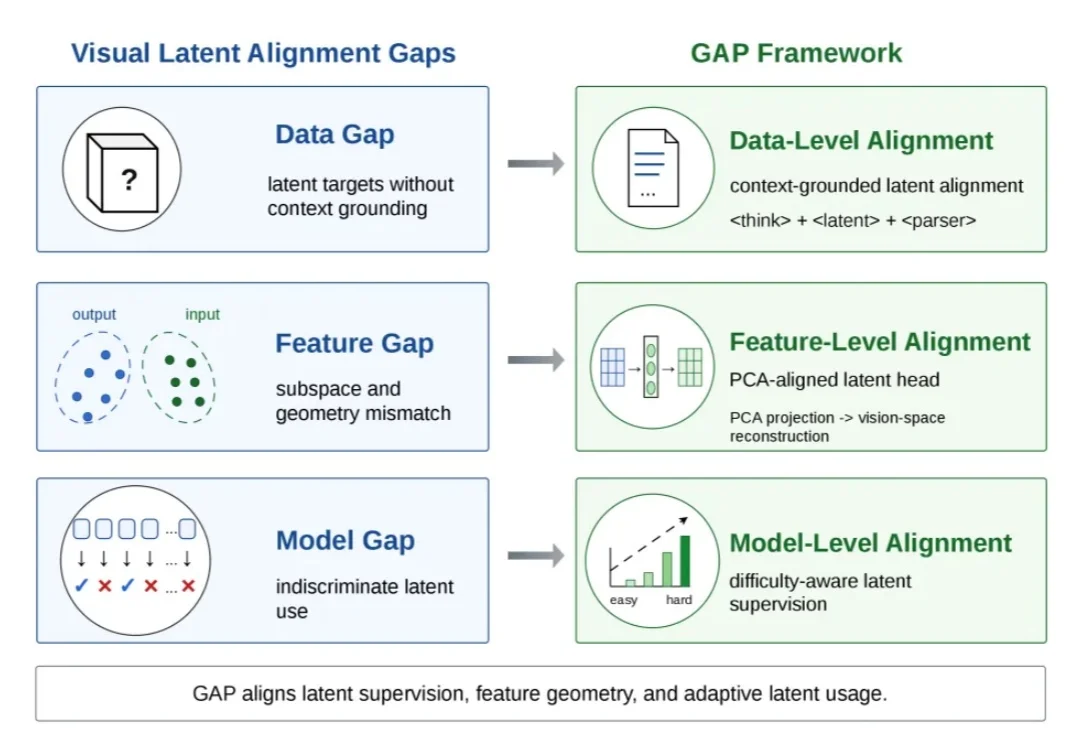
视觉latent reasoning为什么不稳?这篇论文从特征空间找到了关键缺口导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。
来自主题: AI技术研报
5509 点击 2026-06-16 13:56