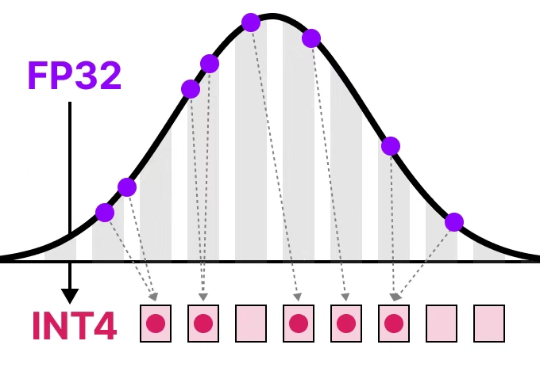
清华第三代Sage注意力发布!提速5倍,精度不降,训推都能用
清华第三代Sage注意力发布!提速5倍,精度不降,训推都能用清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。
来自主题: AI技术研报
8895 点击 2025-07-08 12:08
 搜索
搜索
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。
“上线 4 个月,DAU 破百万,累计用户破千万,用户日均对话次数超 9 次,跻身国内同类产品第一梯队 ——元石科技的‘问小白’用生成式推荐重新定义AI时代的信息获取与消费。
2017 年,一篇《Attention Is All You Need》论文成为 AI 发展的一个重要分水岭,其中提出的 Transformer 依然是现今主流语言模型的基础范式。尤其是在基于 Transformer 的语言模型的 Scaling Law 得到实验验证后,AI 领域的发展更是进入了快车道。

“在百川智能的那段时间,我和同事们始终处在一种很亢奋的状态。尽管我们常常工作到深夜,甚至一两点钟才下班,但内心非常地充实和开心。”如今回忆起那段经历时,前百川工具链负责人徐文健的眼中依然有光。

你有没有想过,为什么在这个云计算和AI横行的时代,PDF文档处理依然是企业最大的痛点之一?想象一下这样的场景:一份包含数百页的贷款申请文档躺在银行系统里,等待人工审核,而申请人只能苦苦等待几天甚至几周才能知道结果。与此同时,医院里的医疗记录还在用打印机输出,然后手工传递给下一个医生。
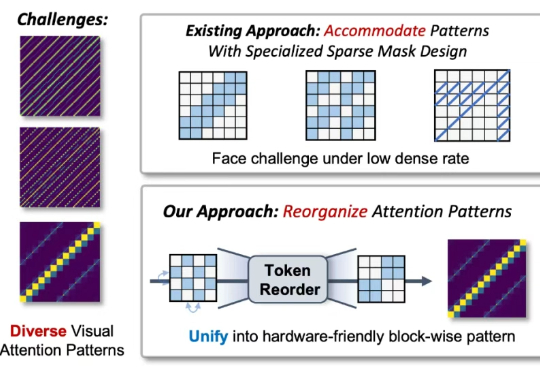
近年来,随着视觉生成模型的发展,视觉生成任务的输入序列长度逐渐增长(高分辨率生成,视频多帧生成,可达到 10K-100K)。
在经过深度思考后,我有了一个大胆的猜想:我们一直在用错误的框架理解它,大家都把它当作"更好的编程工具",但我越用越觉得,这根本不是一个编程工具,而是一个披着终端外衣的通用 AI agent。正好周末看了Anthropic 产品负责人 Michael Gerstenhaber 的最新一期访谈,
你有没有想过,一个因为开发作弊工具被哥伦比亚大学开除的 21 岁学生,竟然能在短短几个月内获得 a16z 领投的 1500 万美元融资?
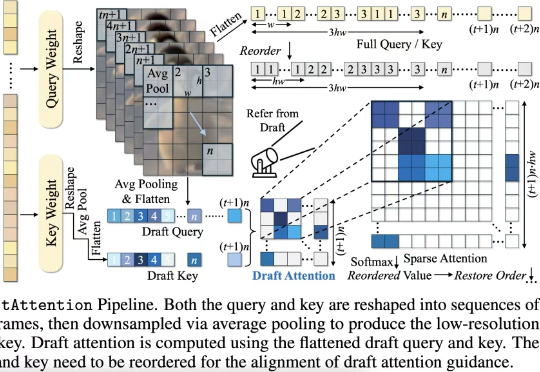
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。

每年数百万患者在医疗转诊中“消失”,这家纽约创业公司用AI重建连接,估值半年飙升至6.05亿美元。