NVIDIA Tensor Core 的演变:从 Volta 到 Blackwell
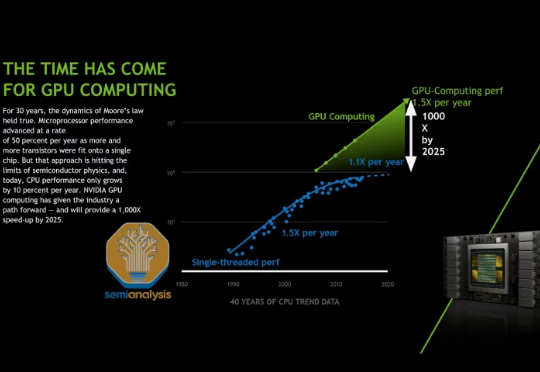
NVIDIA Tensor Core 的演变:从 Volta 到 Blackwell在我们去年 AI Scaling Laws article from late last year中,我们探讨了多层 AI 扩展定律如何持续推动 AI 行业向前发展,使得模型能力的增长速度超过了摩尔定律,并且单位 token 成本也相应地迅速降低。
来自主题: AI技术研报
9646 点击 2025-06-24 11:09