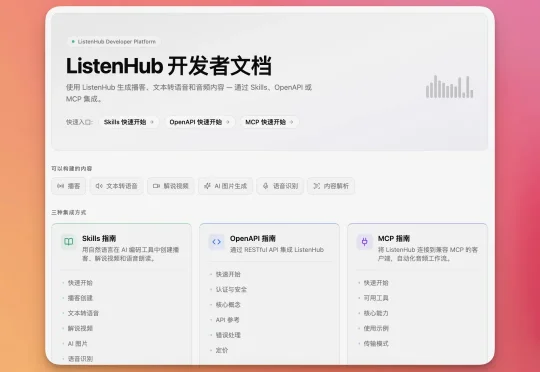
ListenHub ASR 语音识别 API 全新上线,无限免费!无限免费!
ListenHub ASR 语音识别 API 全新上线,无限免费!无限免费!ListenHub ASR 语音识别 API 全新上线,无限免费。 API 特点: 本地离线转录,无需 API Key,安装即可使用。专为 Agent 设计,方便你的 Claude Code 和龙虾🦞直接接入自动化工作流。
来自主题: AI资讯
9698 点击 2026-03-13 19:12
 搜索
搜索
ListenHub ASR 语音识别 API 全新上线,无限免费。 API 特点: 本地离线转录,无需 API Key,安装即可使用。专为 Agent 设计,方便你的 Claude Code 和龙虾🦞直接接入自动化工作流。
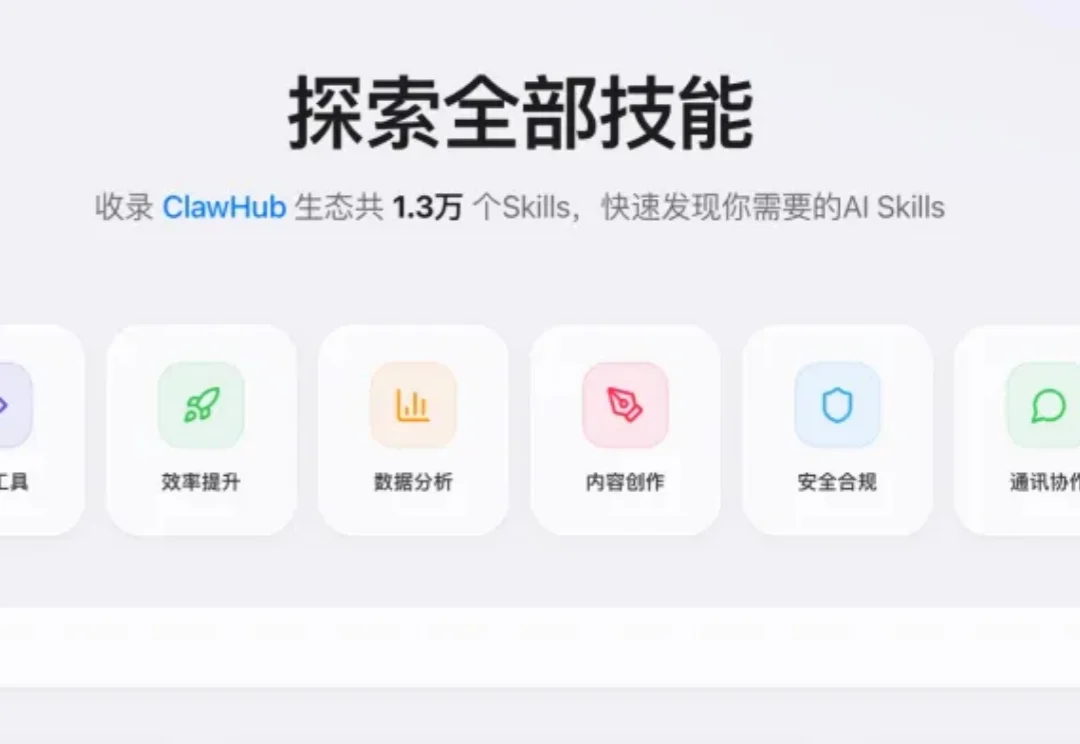
向各位🦞友报告,腾讯龙虾技能市场的建设情况👇
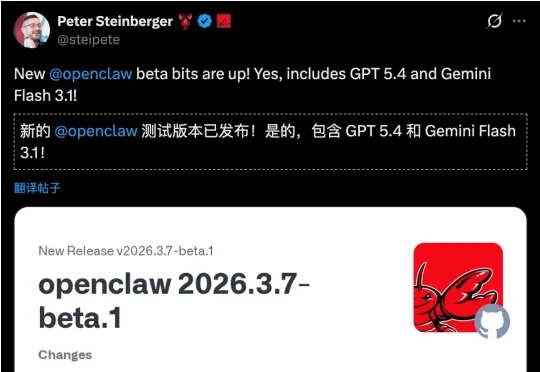
OpenClaw推出v2026.3.7-beta.1,史上最密集一次更新:89项提交、200+Bug修复,核心亮点是全新ContextEngine插件接口——上下文管理终于可以「自由插拔」,不动核心代码就能换策略。这次更新值得每一个做AI Agent的人认真看。

3月6日,腾讯混元发布了一篇名为“HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing”的技术报告。提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!
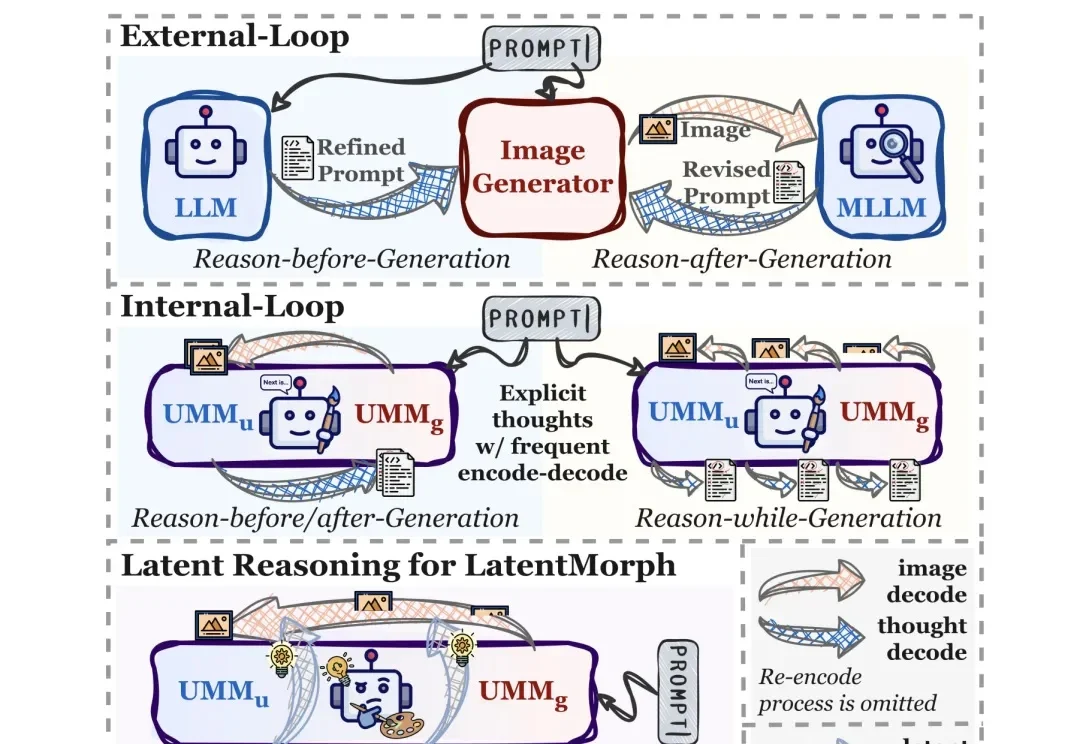
人类在创作艺术时,大脑并非一味地输出,而是在每一笔落下时都在进行着复杂的、难以言表的 “视觉优化”。
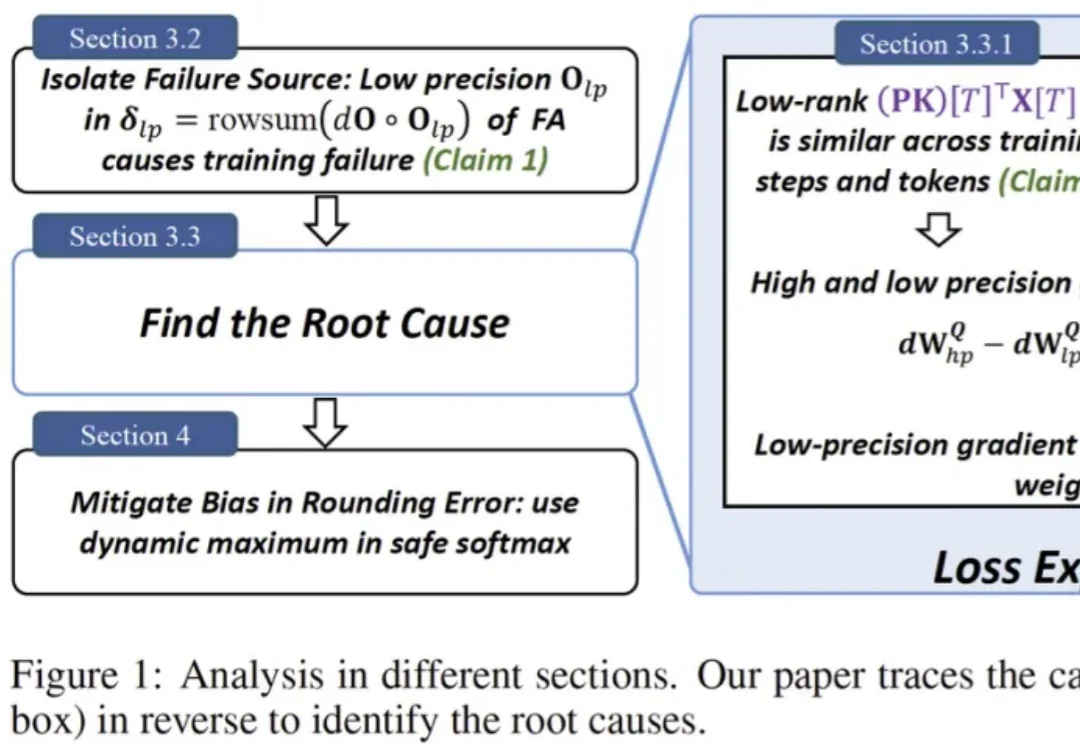
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
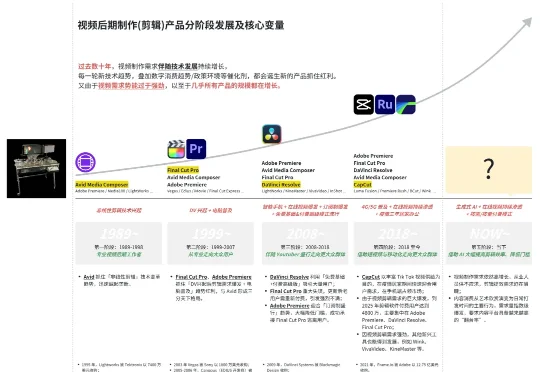
据悉,专注视频后期 AI Agent 的 Vattention(时空注力)已完成数百万美元种子轮融资,由青锐资本、百度风投、常垒资本联合投资。该公司由计算机科班出身、曾任阿里淘系核心产品总监、沉浸专业视频制作领域多年的连续创业者钟超(花名 船长)创立。本轮融资将主要用于核心团队组建与技术研发,推动其三大核心引擎(MACE、ACE、PACE)的产品化落地。

最近,英伟达又发布了一个炸裂成果。英伟达高级工程师Bing Xu开源了VibeTensor项目,并且表示:「这是第一个完全由 AI 智能体生成的深度学习系统,没有一行人类编写的代码。」
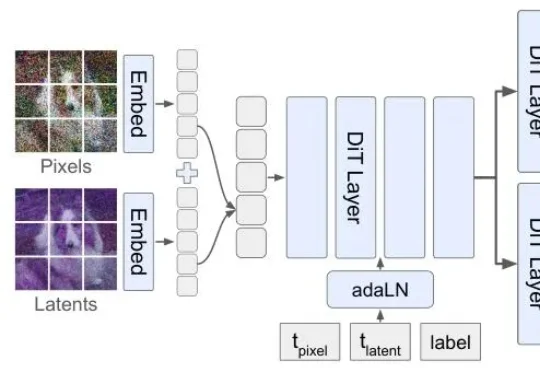
但扩散模型生图,顺序真的对吗?李飞飞团队最新论文提出的Latent Forcing方法直接打破了这一共识,他们发现生成的质量瓶颈不在架构,而在顺序。