
ListenHub PPT 正式上线,首个自带视频讲解的AI PPT来了。
ListenHub PPT 正式上线,首个自带视频讲解的AI PPT来了。今天,我们非常高兴地向大家宣布: ListenHub PPT 正式上线了。在开发这款产品的过程中,我们一直在思考:如何让创作者从繁琐的格式调整和素材制作中解放出来,回归内容本身?于是,我们带来了这款全球首个自带视频讲解的 PPT。
来自主题: AI资讯
9506 点击 2025-12-11 10:11
 搜索
搜索
今天,我们非常高兴地向大家宣布: ListenHub PPT 正式上线了。在开发这款产品的过程中,我们一直在思考:如何让创作者从繁琐的格式调整和素材制作中解放出来,回归内容本身?于是,我们带来了这款全球首个自带视频讲解的 PPT。
一直以来,传统 MAS 依赖自然语言沟通,各个 LLM 之间用文本交流思路。这种方法虽然可解释,但冗长、低效、信息易丢失。LatentMAS 则让智能体直接交换内部的隐藏层表示与 KV-cache 工作记忆,做到了:

在本次 Z Potential 独家专访中,我们邀请到了 Striker Venture Partners 合伙人、Skild AI 与 Reflection AI 的早期投资人 Brian Zhan,深度解析他在 AI 时代如何快速投出明星级别的独角兽公司。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,
这两年,写代码这件事变了。GitHub Copilot、Cursor、Devin 一路登场,工程师开始习惯“打一段话,几千行代码自己长出来”。写得出东西,变得前所未有地容易。但很快大家发现,真正拖住上线节奏的,不再是「能不能写出来」,而是「敢不敢放上生产环境」——代码量指数级增长,验证、回归、极端场景覆盖反而被彻底压缩,测试成了 AI 时代新的“硬瓶颈”。
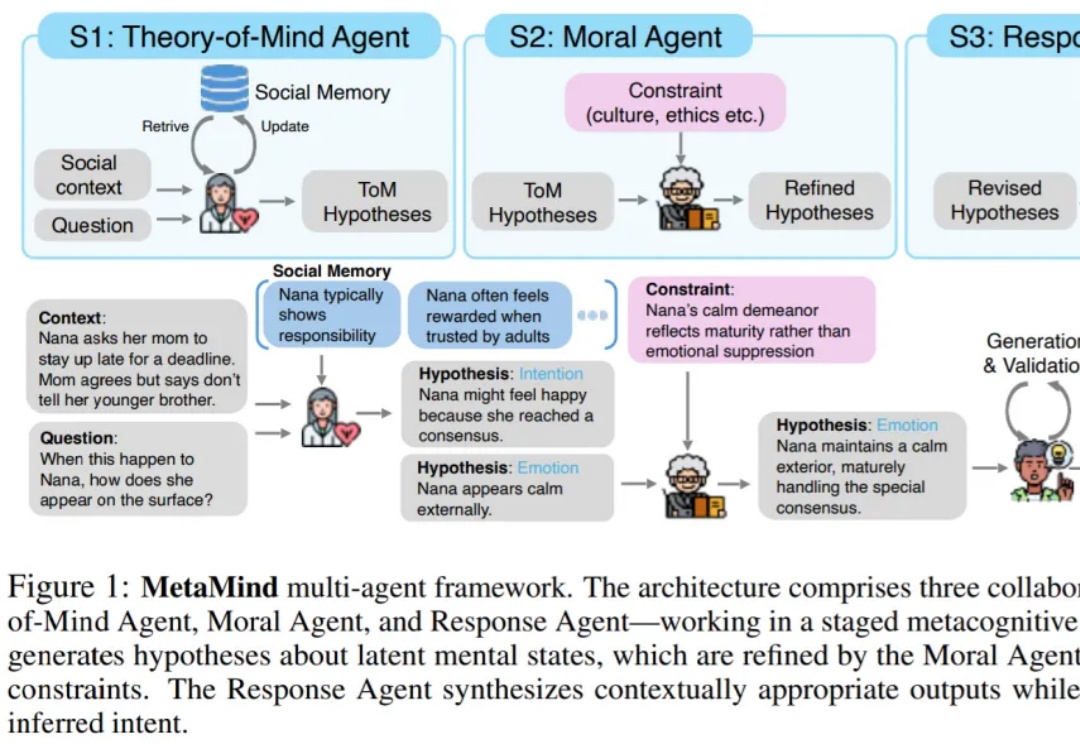
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice

无需额外训练即可适配预训练生成模型的编辑方法,凭借灵活、高效的特性,已成为视觉生成领域的研究热点。这类方法通过操控 Attention 机制(如 Prompt-to-Prompt、MasaCtrl)实现文本引导编辑,但当前技术存在两大核心痛点,严重限制其在复杂场景的应用
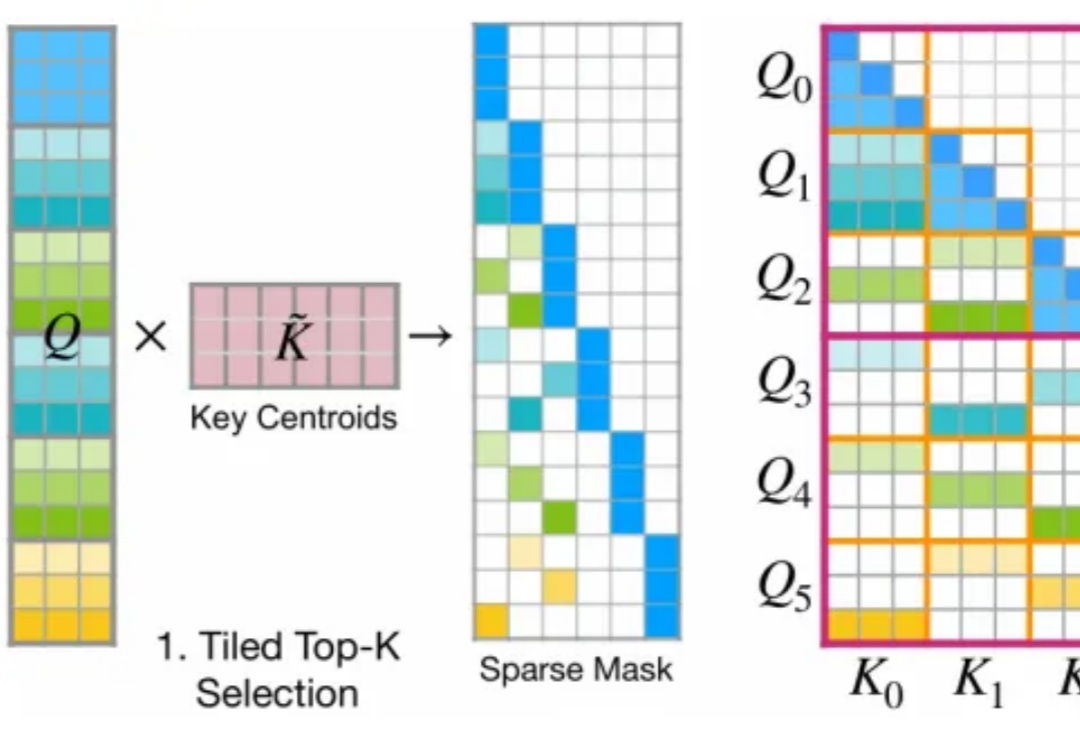
今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。
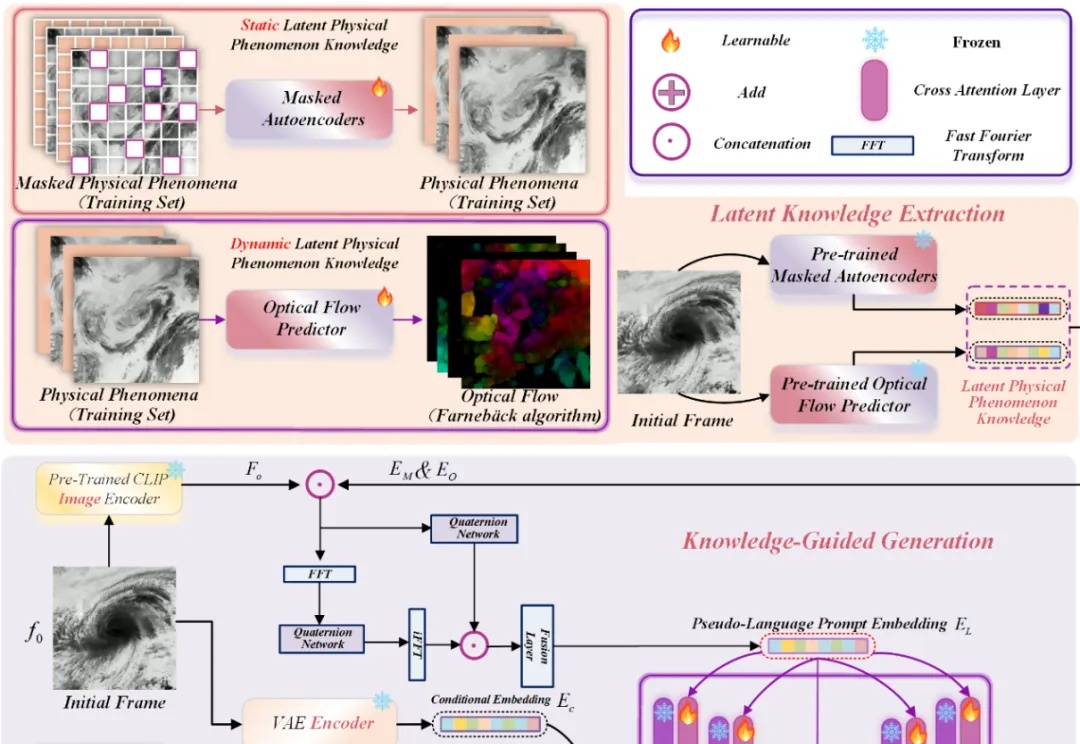
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。

近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),