
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗
清华耶鲁推理模型新范式:动态推理实现高效测试时扩展,大大节省Token消耗推理性能提升的同时,还大大减少Token消耗!
来自主题: AI技术研报
7957 点击 2025-04-08 09:25
推理性能提升的同时,还大大减少Token消耗!
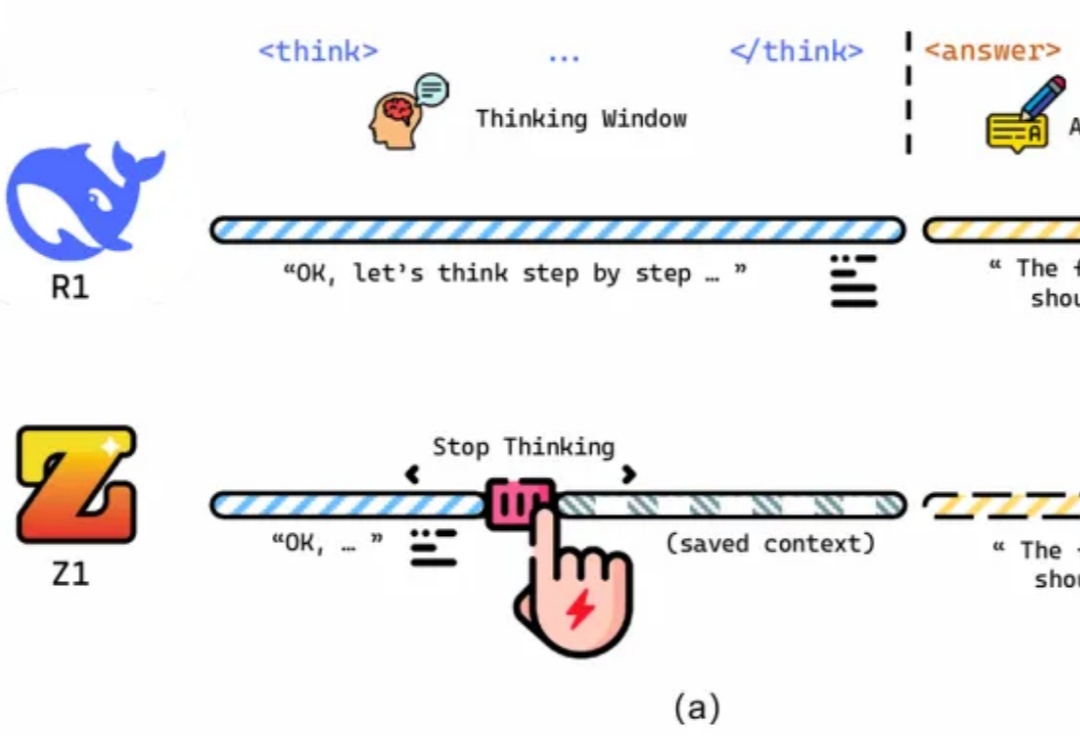
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。
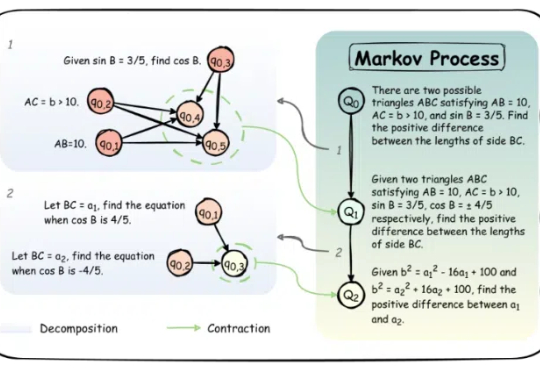
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。

Ilya Sutskever(前 OpenAI 联合创始人兼首席科学家)在前几天召开的 NeurIPS 会议上表示,大模型的预训练已经走到了尽头。而 Noam Brown(OpenAI 研究员,曾带领团队开发出在德州扑克中战胜职业选手的 AI 系统 Pluribus)在近期关于 OpenAI O1 发布的采访中提到,提升 Test-Time Compute 是提升大模型答案质量的关键。

不必增加模型参数,计算资源相同,小模型性能超过比它大14倍的模型!