大模型也会想太多?清华等提出TaH:跳过93%无效迭代,准确率反而提升
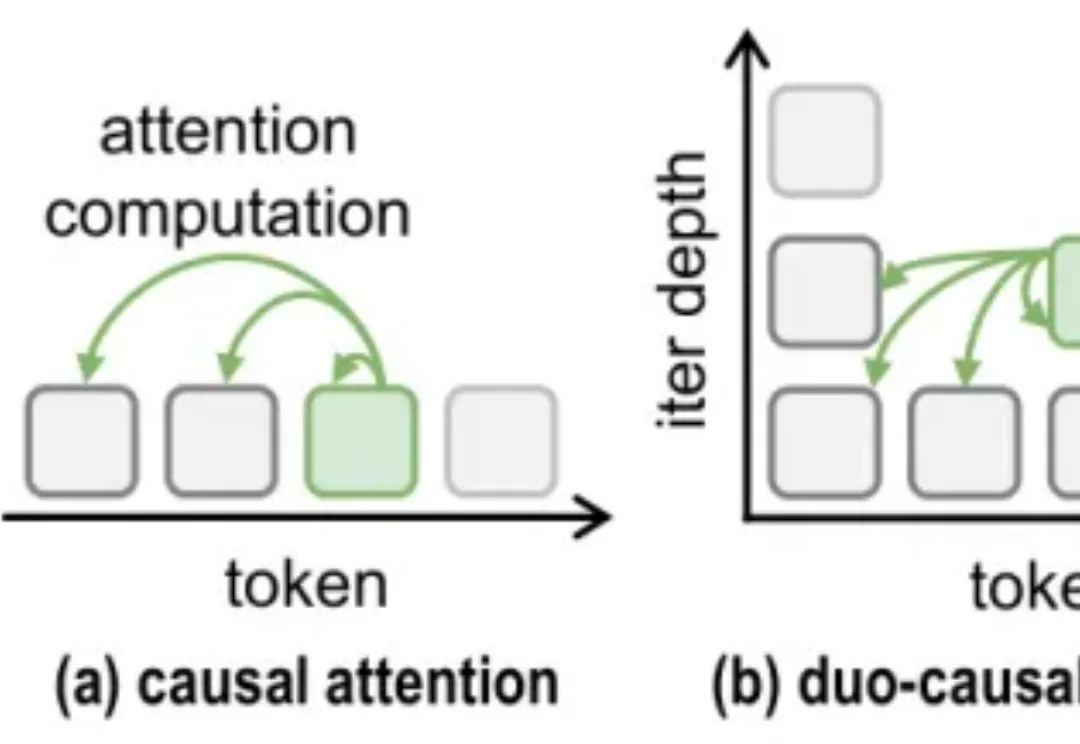
大模型也会想太多?清华等提出TaH:跳过93%无效迭代,准确率反而提升随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。
来自主题: AI技术研报
7707 点击 2026-05-22 08:44
 搜索
搜索
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。