
在义乌,每一个Token都不会浪费
在义乌,每一个Token都不会浪费AI工具最残酷的检验场,不在硅谷,而在义乌。
来自主题: AI资讯
10146 点击 2026-05-14 10:29
 搜索
搜索
AI工具最残酷的检验场,不在硅谷,而在义乌。
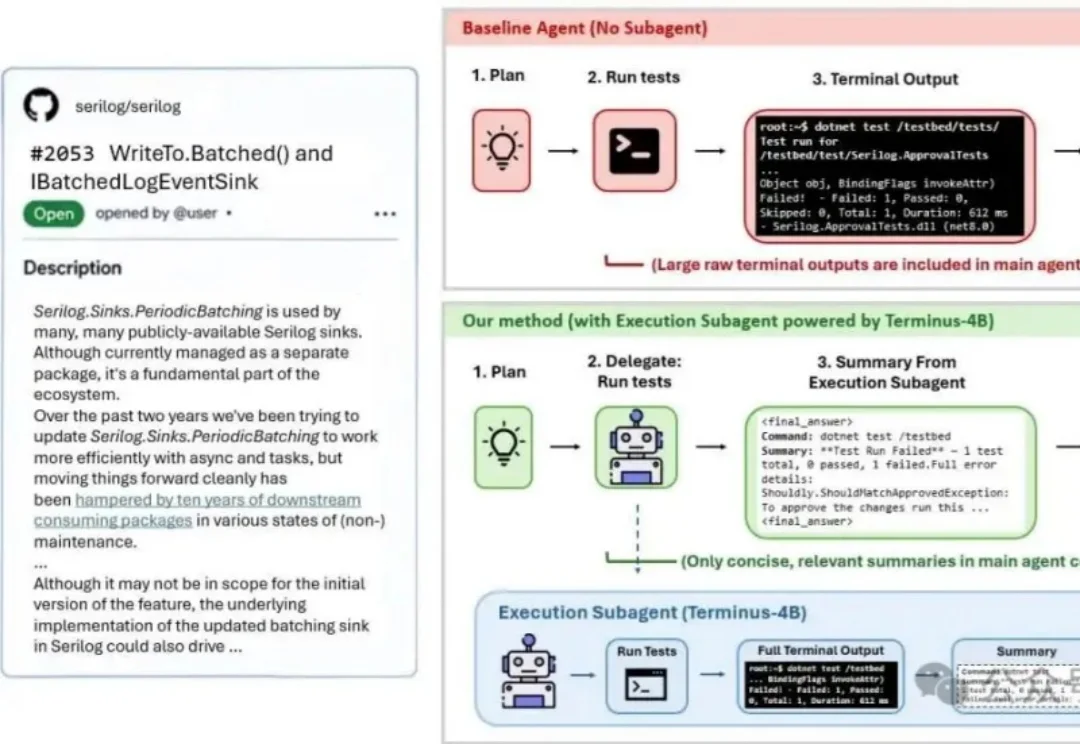
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

上次 WinClaw 的超级 VIP 计划推出 10000 个免 token 名额时我就想发,可惜我看到的时候名额已经被抢空。今天突然刷到活动又返场了!5 月 7 日到 5 月 17 日,又有 8000 个 Token 永久免费名额可以申请
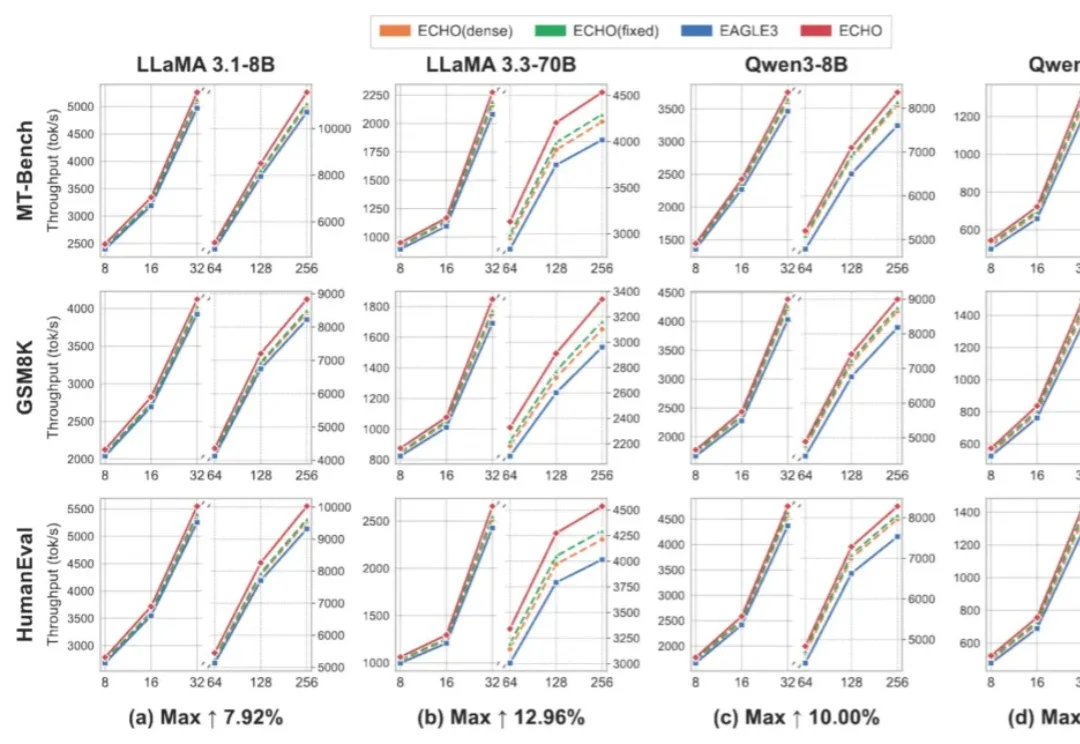
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。

5月12日,小米集团总裁卢伟冰发文:为回馈全球开发者,小米正式启动「MiMo Orbit 100T Token 计划」,面向全球 AI 用户免费发放 Token 权益,计划在 30 天内累计发放 100 万亿 Token。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
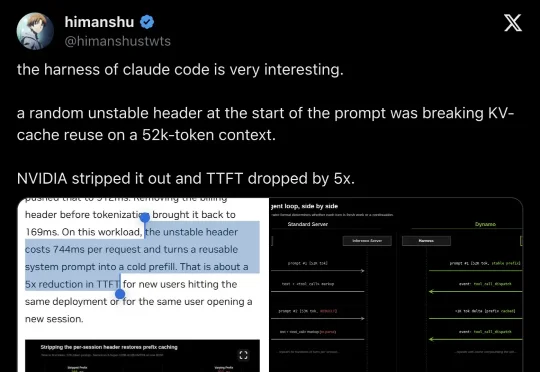
NVIDIA Dynamo 团队发现,Claude Code 向自定义端点发送请求时,prompt 最前面会带一行 session-specific billing header。这行 header 每个 session 都变,导致 52K token 的稳定前缀在 KV cache 中无法复用——TTFT 从 168ms 飙到 912ms。Dynamo 加了一个 `

大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。