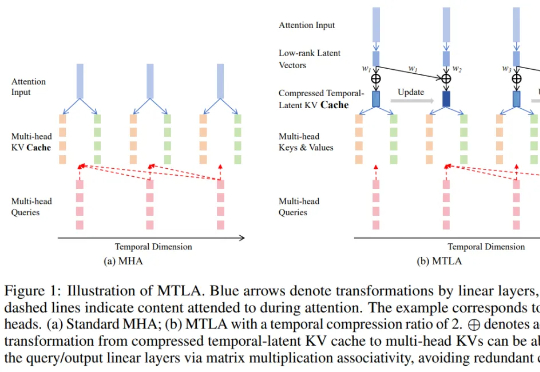
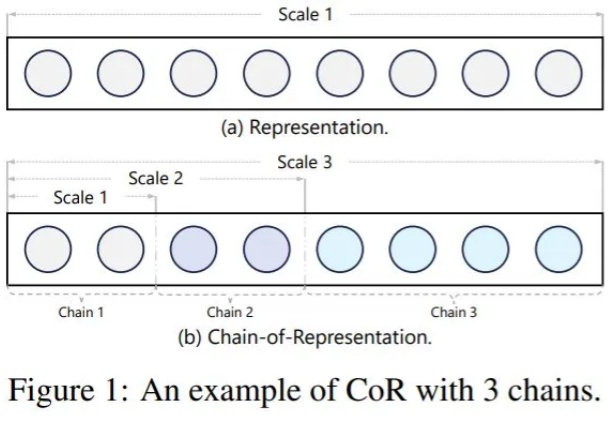
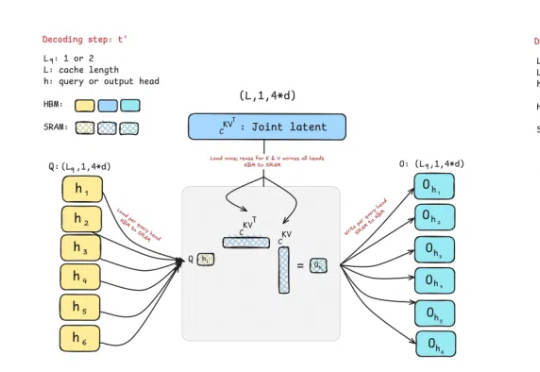
技术Blog-4 | 新一代InfLLM:可训练的稀疏注意力机制
技术Blog-4 | 新一代InfLLM:可训练的稀疏注意力机制本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。
来自主题: AI技术研报
9246 点击 2025-06-16 15:24