
近8年后,谷歌Transformer继任者「Titans」来了,上下文记忆瓶颈被打破
近8年后,谷歌Transformer继任者「Titans」来了,上下文记忆瓶颈被打破正如论文一作所说,「新架构 Titans 既比 Transformer 和现代线性 RNN 更有效,也比 GPT-4 等超大型模型性能更强。」
来自主题: AI技术研报
8656 点击 2025-01-16 09:54
 搜索
搜索
正如论文一作所说,「新架构 Titans 既比 Transformer 和现代线性 RNN 更有效,也比 GPT-4 等超大型模型性能更强。」
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。
「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman
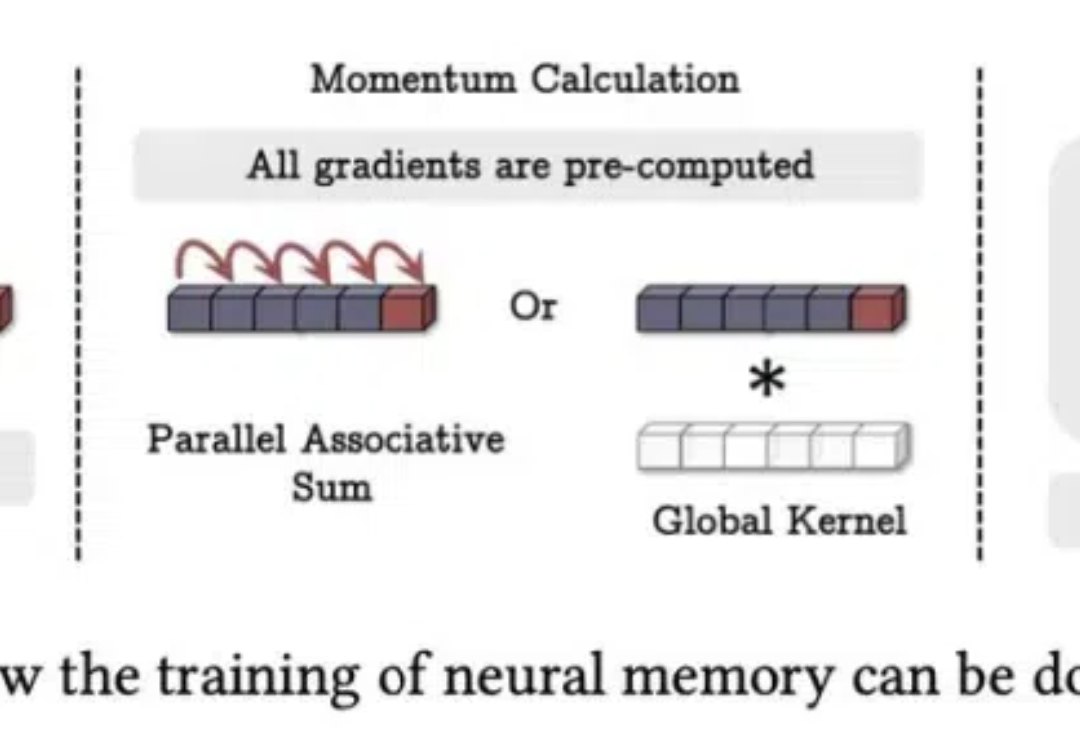
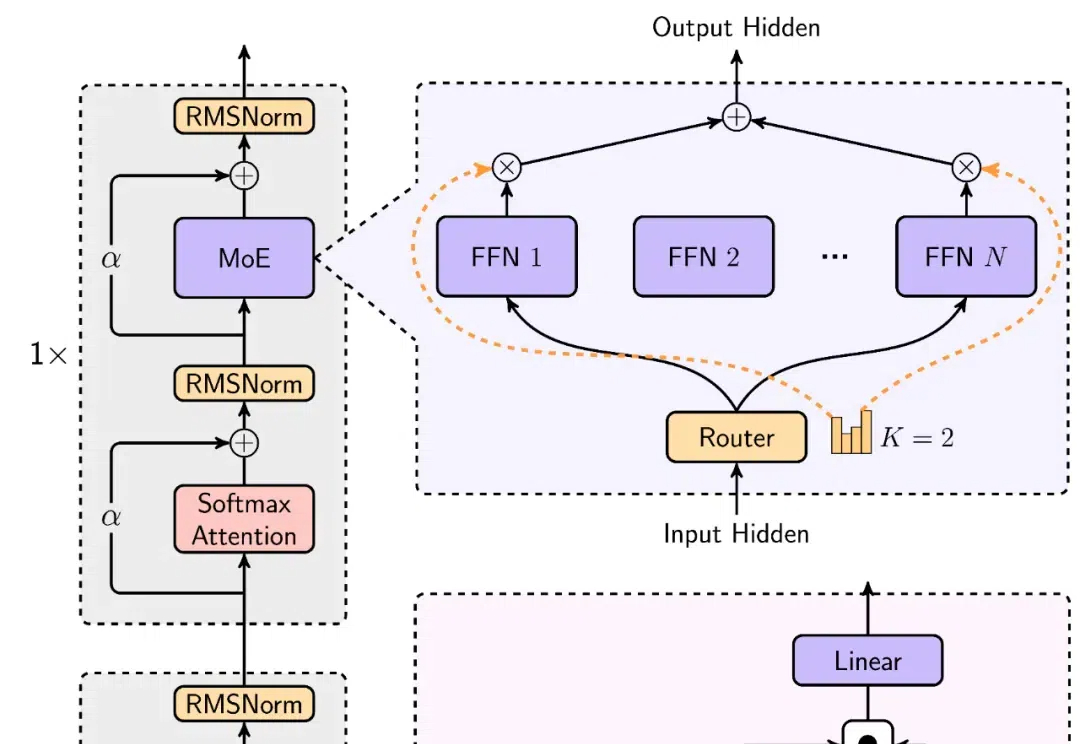
想挑战 Transformer 的新架构有很多,来自谷歌的“正统”继承者 Titan 架构更受关注。
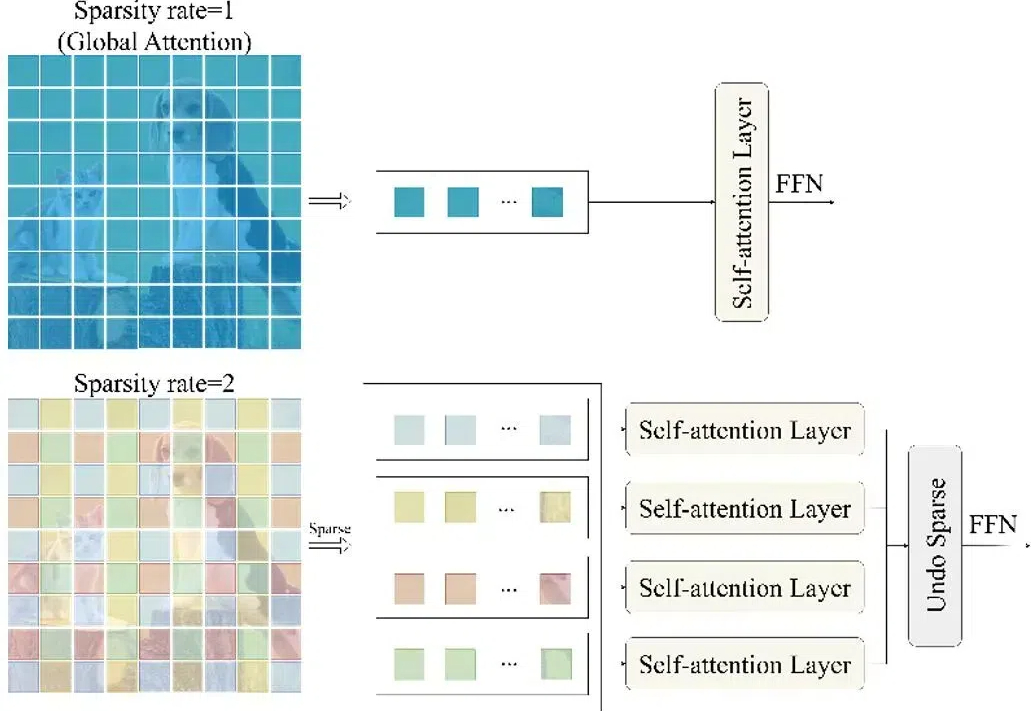
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。
要做大模型领域的安卓和Linux。
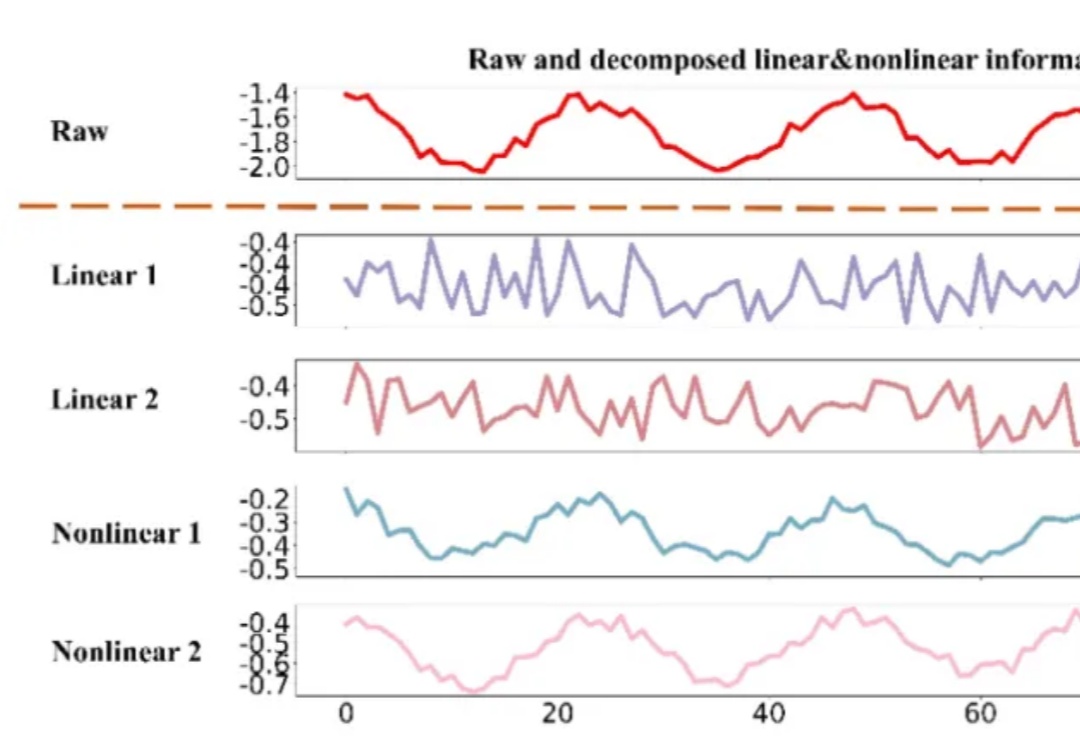
时间序列数据,作为连续时间点的数据集合,广泛存在于医疗、金融、气象、交通、能源(电力、光伏等)等多个领域。有效的时间序列预测模型能够帮助我们理解数据的动态变化,预测未来趋势,从而做出更加精准的决策。

2022年,我们打赌说transformer会统治世界。 我们花了两年时间打造Etched chip,这是世界上第一个用于transformer(ChatGPT中的“T”)的专用芯片。
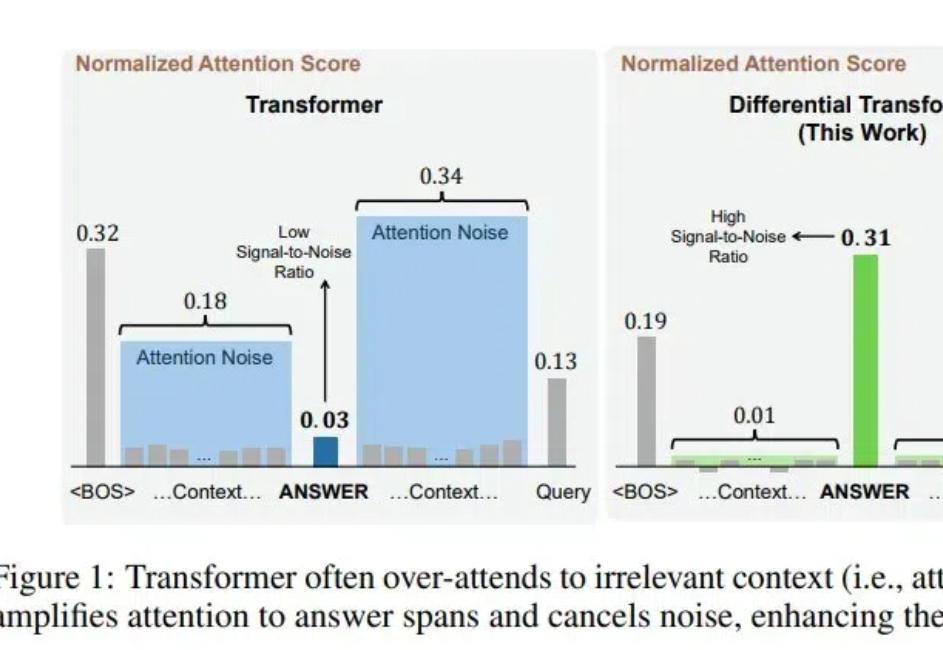
ViT核心作者Lucas Beyer,长文分析了一篇改进Transformer架构的论文,引起推荐围观。

Transformer——支撑像 OpenAI 的 ChatGPT 和 Anthropic 的 Claude 这样的聊天机器人的基础 AI 技术——正在帮助机器人更快地学习。