

全球首个多模态创意营销 Claw 来了,好创意比以前更值钱了
全球首个多模态创意营销 Claw 来了,好创意比以前更值钱了恰好最近,我留意到常用的一个视频生成工具 Vidu,上线了 ViduClaw 「V 龙」——全球首个多模态创意营销 Claw。虽然此前已有不少 AI 厂商推出了自家的「Claw」,但作为视频模型厂商,而且做得这么完整的,Vidu 是我见到的业内头一个。
来自主题: AI资讯
8452 点击 2026-03-28 20:44
恰好最近,我留意到常用的一个视频生成工具 Vidu,上线了 ViduClaw 「V 龙」——全球首个多模态创意营销 Claw。虽然此前已有不少 AI 厂商推出了自家的「Claw」,但作为视频模型厂商,而且做得这么完整的,Vidu 是我见到的业内头一个。

昨天在群里闲逛,发现观猹上新了一个龙虾测评专区。
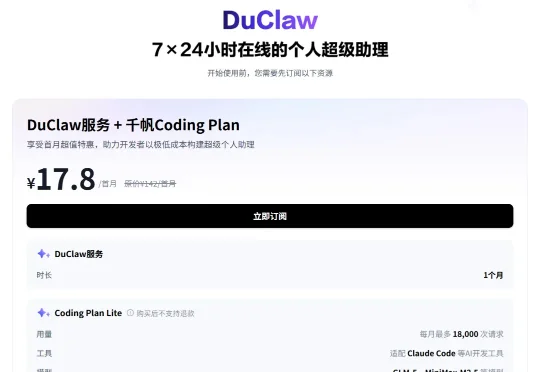
为了把降本增效做到极致,我对比了一圈市面上的方案,最后选定了一个傻瓜式且极具性价比的搭建途径:百度智能云推出的 DuClaw。 一台轻量应用服务器9块9,再搭配千帆首月的 Coding Plan 套餐 7.9元,共计 17.8 元 👇

数学家陶哲轩,公开了AI新身份——SAIR Foundation联合创始人。之前,他是举世闻名的数学天才,年少成名的传奇数学家、13岁加冕IMO的最年轻金牌得主……24岁就成为加州大学洛杉矶分校(UCLA)史上最年轻的终身正教授。

加州大学洛杉矶分校(UCLA)数学教授 Ernest Ryu 发推称:「我使用 ChatGPT 解决了凸优化中的一个未曾被解决的问题。」随后,他通过一系列推文介绍了自己与 ChatGPT 的联合成果。
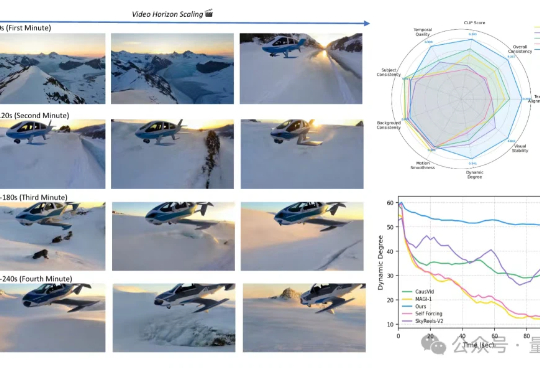
从5秒到4分钟,Sora2也做不到的分钟级长视频生成,字节做到了!这就是字节和UCLA联合提出的新方法——Self-Forcing++,无需更换模型架构或重新收集长视频数据集,就能轻松生成分钟级长视频,也不会后期画质突然变糊或卡住。

大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。

刚刚,加州大学洛杉矶分校(UCLA)副教授周博磊官宣加入机器人初创公司 Coco Robotics,专注于人行道自动驾驶这一难题!
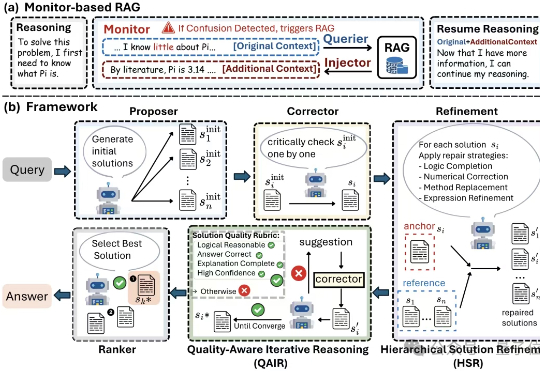
就在最近,由耶鲁大学唐相儒、王昱婕,上海交通大学徐望瀚,UCLA万冠呈,牛津大学尹榛菲,Eigen AI金帝、王瀚锐等团队联合开发的Eigen-1多智能体系统实现了历史性突破

就在昨天,来自UCLA的两位研究者黄溢辰和杨林做了一件让整个AI圈都震惊的事。他们用Google的Gemini 2.5 Pro模型,在2025年国际数学奥林匹克竞赛中拿下了金牌水平的成绩,6道题解对了5道。这可不是什么花架子,IMO被公认为是测试AI推理能力的终极试金石,因为它需要的不仅仅是计算,更需要创造性思维和严密的逻辑推理。