
兄弟俩用开源对抗AI训练垄断,还顺手帮模型们修了一堆Bug
兄弟俩用开源对抗AI训练垄断,还顺手帮模型们修了一堆Bug2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?
来自主题: AI资讯
11186 点击 2025-10-28 10:40
 搜索
搜索
2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。

开源微调神器Unsloth带着黑科技又来了:短短两周后,再次优化DeepSeek-R1同款GRPO训练算法,上下文变长10倍,而显存只需原来的1/10!
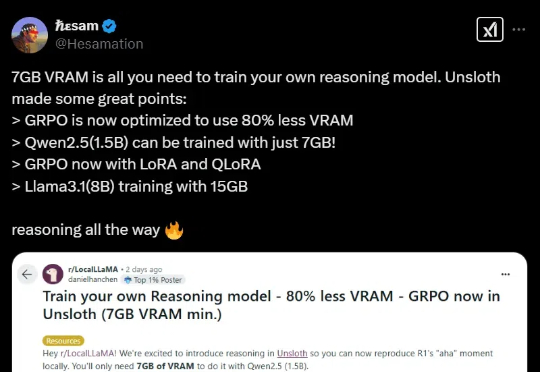
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。

在上一篇文章「Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存」中,我们介绍了Unsloth,这是一个大模型训练加速和显存高效的训练框架,我们已将其整合到Firefly训练框架中,并且对Llama3-8B的训练进行了测试,Unsloth可大幅提升训练速度和减少显存占用。