
屡被质疑的AI检测赛道,华人创业者把产品做到2400万美元ARR
屡被质疑的AI检测赛道,华人创业者把产品做到2400万美元ARR从面世以来,AI 检测工具的准确性就一直屡遭诟病。
来自主题: AI资讯
9623 点击 2026-03-10 10:03
 搜索
搜索
从面世以来,AI 检测工具的准确性就一直屡遭诟病。

近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。

自从OpenClaw爆火后,各种Claw开始轮番登场。NanoClaw、ZeroClaw、PicoClaw刷屏,连卡帕西都坐不住了,为了“抓虾”,他一个百米冲刺奔向苹果店抢Mac Mini,要好好拆解一番爆火的各种Claw们。

驱动具身智能进入通用领域最大的问题在哪里?

Claude登陆火星!这是AI首次在外星上实现了「自动驾驶」。就在刚刚,NASA官方确认:人类历史上首次由AI全权规划的外星行驶任务,圆满完成!此次任务的具体地点在火星上的杰泽罗陨石坑(Jezero Crater)。
2025最后几天,是时候来看点年度宝藏论文了。

当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
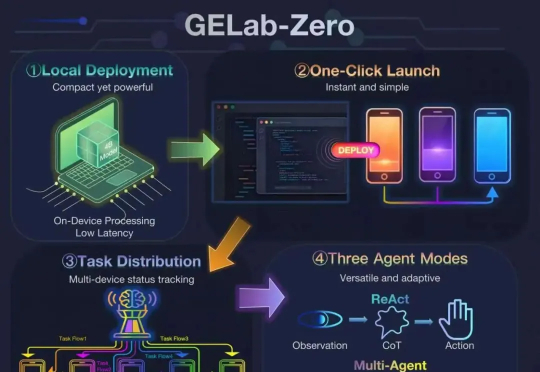
首次将GUI Agent模型与完整配套基建同步开放,支持手搓党一键部署!这就是阶跃星辰刚刚开源的GELab-Zero。其中4B版本的GUI Agent模型在手机端、电脑端等多个GUI榜单上全面刷新同尺寸模型性能纪录,取得SOTA成绩。

CMU×Meta 联手,姚班李忆唐最新论文成果。
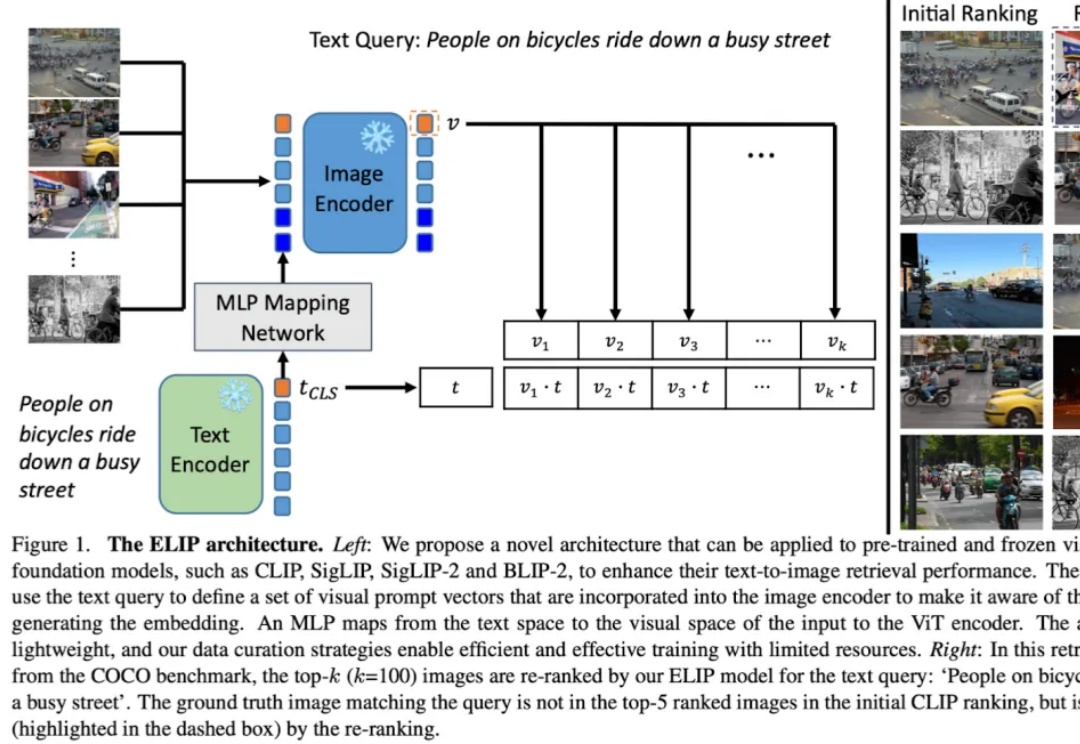
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。