架构解耦是统一多模态模型所必须的吗?全新AIA损失:No
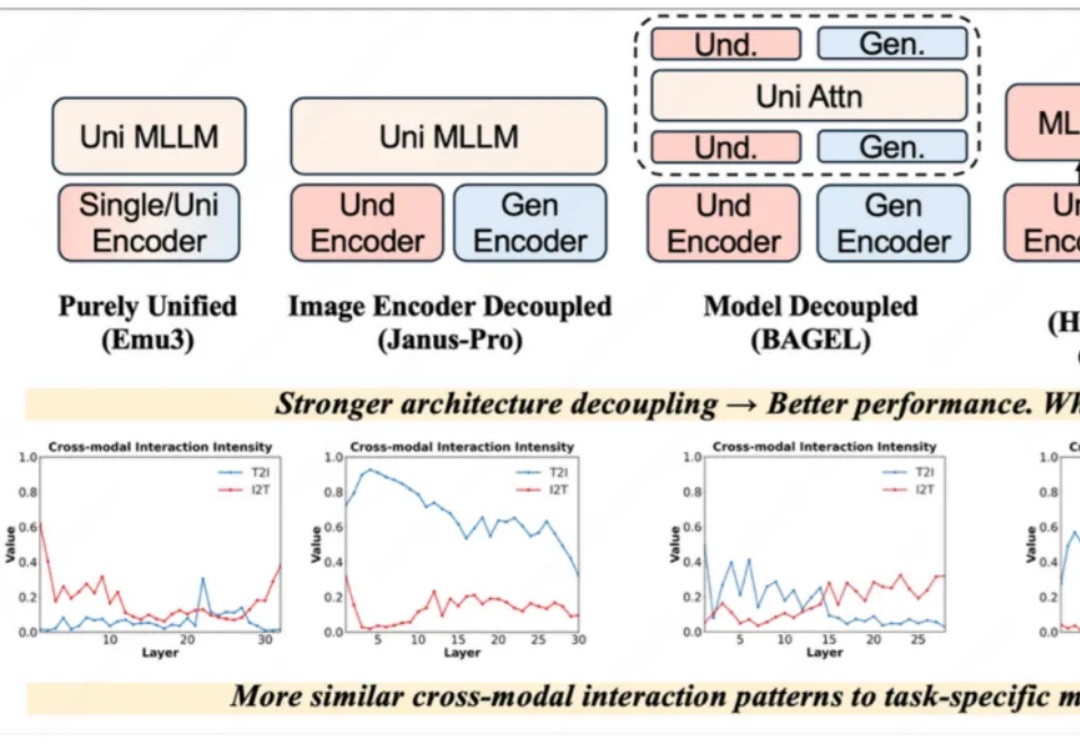
架构解耦是统一多模态模型所必须的吗?全新AIA损失:No近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。
来自主题: AI技术研报
9131 点击 2025-12-02 15:17