AI应用元年,只会yes,无视风险?软件开发的航行日志全面开源
AI应用元年,只会yes,无视风险?软件开发的航行日志全面开源AI写代码的风险隐藏在看似正确的代码中,可能引发数据泄露或资产损失。Narwhal AI Code Risks开源项目整理了真实案例、早期信号和典型风险路径,帮助开发者提前识别隐患,避免重蹈覆辙。
来自主题: AI资讯
6289 点击 2026-06-16 10:24
 搜索
搜索
AI写代码的风险隐藏在看似正确的代码中,可能引发数据泄露或资产损失。Narwhal AI Code Risks开源项目整理了真实案例、早期信号和典型风险路径,帮助开发者提前识别隐患,避免重蹈覆辙。
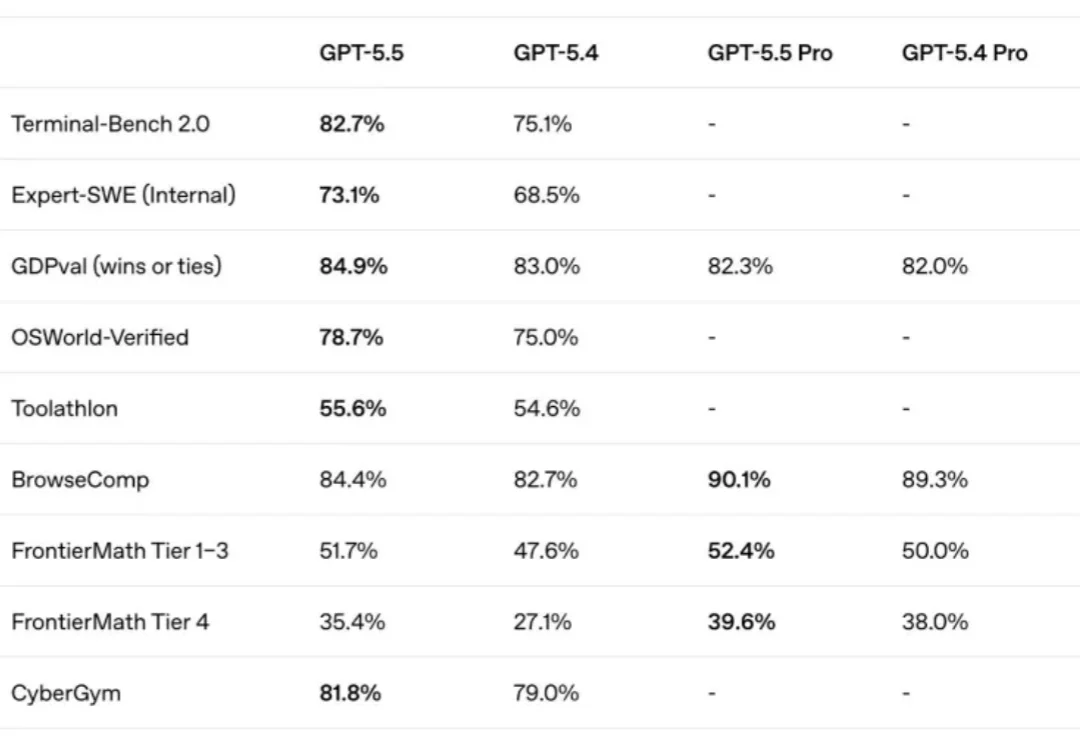
随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。

刚刚,AI圈发生了一件很不寻常的事。Sam Altman、Dario Amodei、Demis Hassabis……一群平时打得最凶的人,把名字签在了同一封公开信上。他们联合呼吁美国国会:立法强制筛查所有合成DNA订单。

今年4-5月,AI信息安全迎来「水门事件级」窗口:攻方落地、守方应急、噪音失控、治理失灵同时暴发。Anthropic主动封印Claude Mythos,只因它强大到必须送进末日火山。

魔法打败魔法的「骚操作」,属实把我看乐了。

科技行业还在收缩,网络安全岗位却抢不到人,连OpenAI也开出44.5万美元高薪招揽安全人才。征兆4月已现:Anthropic的Mythos一个月就挖出超1万个高危漏洞。漏洞发现正被AI加速,网络安全的真正瓶颈,已转向验证与修补。

GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
![[翻译] AI Agent 的 Zero Trust 框架|Anthropic 安全白皮书](https://www.aitntnews.com/pictures/2026/5/28/a5aa95a5-5a65-11f1-add0-fa163e47d677.webp)
Zero Trust 是一套安全架构,核心前提很简单:不信任任何东西,必须验证一切

Gemini 3.5的闯祸实录。

法国巴黎银行正与法国人工智能初创公司 Mistral AI 及其他合作伙伴合作,为应对 Anthropic 旗下 Mythos 等新模型带来的网络安全威胁做准备。