ICML 2026|拒绝大力出奇迹,PRISM框架让dLLM也能高效Test-Time Scaling
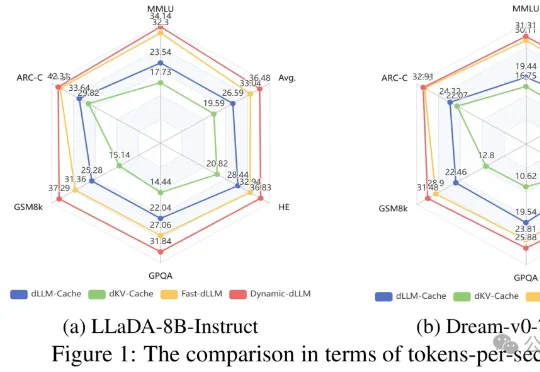
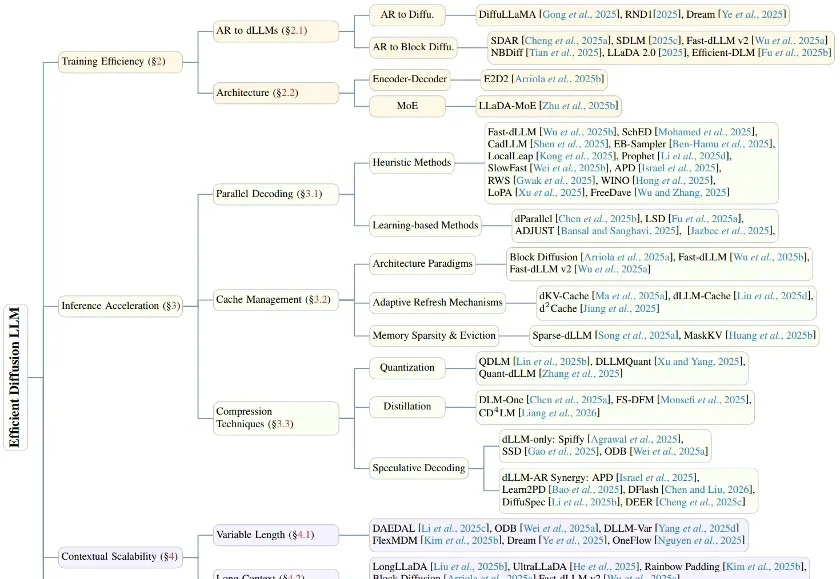
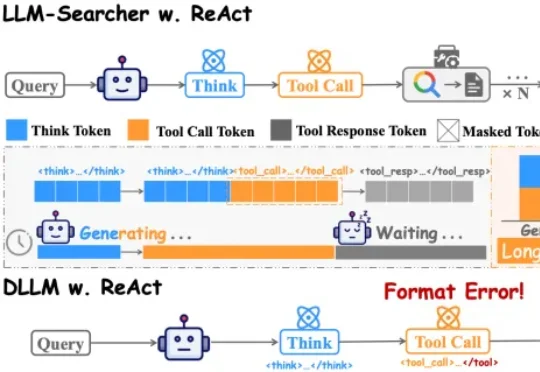
ICML 2026|拒绝大力出奇迹,PRISM框架让dLLM也能高效Test-Time Scaling近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。
来自主题: AI技术研报
6893 点击 2026-05-11 16:09