

拒绝「盲修」:JarvisEvo 如何让 Agent 像人类一样拥有「视觉反思」能力?
拒绝「盲修」:JarvisEvo 如何让 Agent 像人类一样拥有「视觉反思」能力?在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的「懂」修图吗?
来自主题: AI技术研报
6435 点击 2025-12-24 15:01
在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的「懂」修图吗?

MiniMax最新旗舰级Coding & Agent模型M2.1,刚刚对外发布了。这一次,它直接甩出了一份硬核成绩单,在衡量多语言软件工程能力的Multi-SWE-bench榜单中,以仅10B的激活参数拿下了49.4%的成绩,超越了Claude Sonnet 4.5等国际顶尖竞品,拿下全球SOTA。

抽奖式的生图体验,确实让很多设计师在尝鲜之后又默默打开了 Photoshop。于是乎,阿里千问团队再次出手,开源了一个叫 Qwen-Image-Layered 的模型,试图从底层逻辑上解决这个问题。

要说这两天AI圈最火的一条消息,莫过于MiniMax正式通过港交所聆讯,即将冲刺IPO。
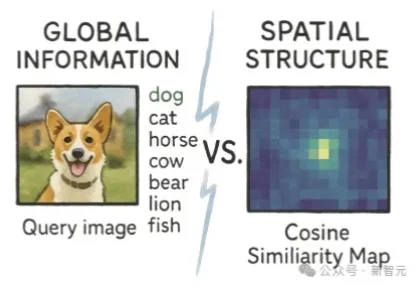
学霸的谎言被揭穿!一篇来自Adobe Research的论文发现,高语义理解并不会提升生成质量,反而可能破坏空间结构。用iREPA简单修改,削弱全局干扰,生成质量立即飙升 。

“中国的OpenAI” 是谁?一众媒体和分析机构给出的答案是:智谱。家中国的大模型 AI 创业公司正在港交所冲刺 IPO。在招股说明书中,它明确宣称:“2025年6月,智谱被美国OpenAI 列为全球主要竞争对手。”
MiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。
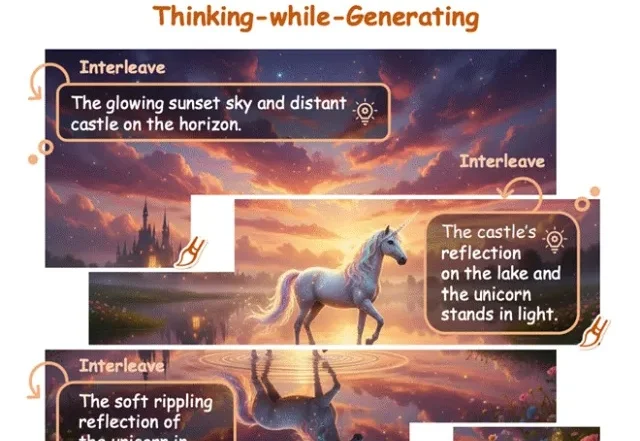
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

2025 年还有一周结束,年底,AI 视频圈又卷起来了。

尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现: