

AI竞争压顶,Meta终于杀入风投
AI竞争压顶,Meta终于杀入风投AI竞争加剧下,Meta面临人才外流和模型性能瓶颈。扎克伯格启动"超级智能单元"招募顶尖AI人才失败后,转向企业风险投资(CVC),通过收购Scale AI和入股NFDG基金,旨在提升竞争力,但优质标的稀缺加剧市场挑战。
来自主题: AI资讯
7731 点击 2025-07-05 18:51
AI竞争加剧下,Meta面临人才外流和模型性能瓶颈。扎克伯格启动"超级智能单元"招募顶尖AI人才失败后,转向企业风险投资(CVC),通过收购Scale AI和入股NFDG基金,旨在提升竞争力,但优质标的稀缺加剧市场挑战。

当全球目光都聚焦在OpenAI、Anthropic、谷歌、Meta等明星AI公司时,真正靠大模型落地大规模盈利的,却是一家相对不太知名的公司——Palantir。

图灵奖大佬向97年小孩哥汇报,这是什么魔幻剧情?小扎砸143亿请来的「数据标注少年」,已荣升Meta首席AI官。一边是小扎上亿美元年薪offer引进新员工,另一边是Meta老将GPU告急不得不熬夜借卡差点头秃。网友们痛呼:太为Meta FAIR的员工难过了……
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。
本文第一作者是上海交通大学计算机学院三年级博士生程彭洲,研究方向为多模态大模型推理、AI Agent、Agent 安全等。通讯作者为张倬胜助理教授和刘功申教授。

又有新瓜了!走了近十名核心研究员后,奥特曼内部备忘录喊话:「传教士终将打败雇佣兵」。另有最新爆料称,小扎挖人几乎癫狂,甚至开出了四年3亿美金的薪酬包。

谁会第一个到达ASI?SemiAnalysis大佬Dylan Patel脱口而出:OpenAI!最近,这位圈内最懂AI和芯片的大佬,毫不留情地戳穿了GPT-4.5惨败的原因,还揭露了Meta仓促模仿DeepSeek结果大翻车的内幕。

最近一段时间,Meta 在人才招聘方面的激进动作可谓震惊了整个行业。扎克伯格似乎下定决心要在 AI 领域打一个翻身仗,不惜重金、大手笔地招揽顶级人才。

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题: 如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?
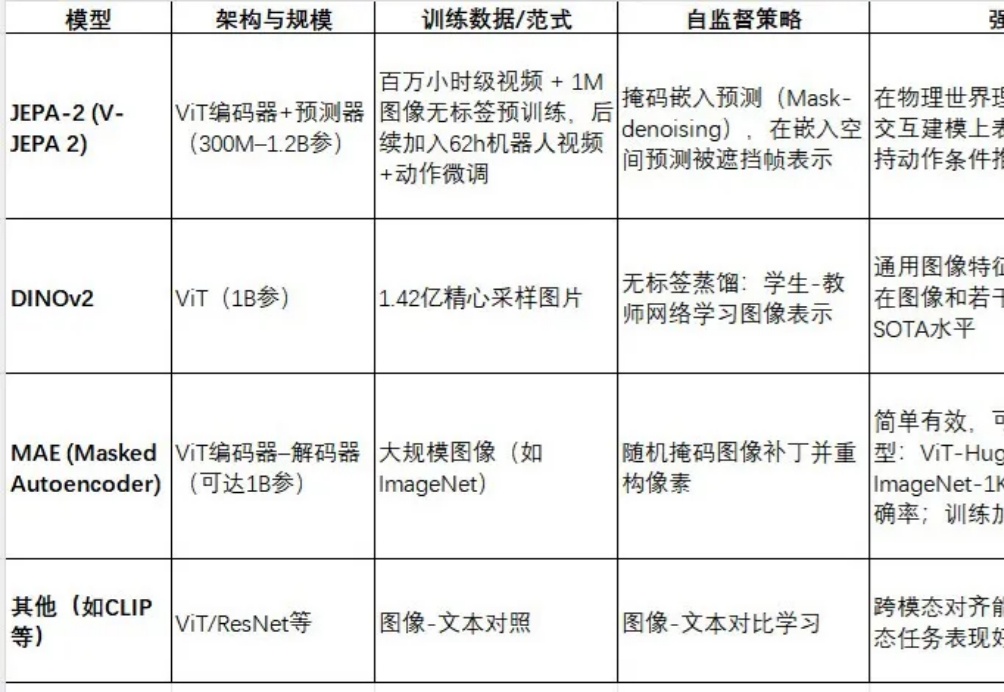
JEPA-2(V-JEPA 2)是Meta最新推出的视频世界模型,采用视图嵌入预测(Joint Embedding Predictive Architecture)框架进行自监督预训练。