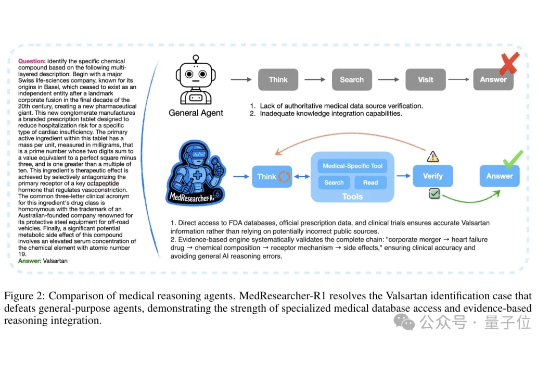
蚂蚁专用模型超越o3!仅用2K训练样本刷新医疗AI榜单纪录
蚂蚁专用模型超越o3!仅用2K训练样本刷新医疗AI榜单纪录不卷参数的专业模型,会不会被通用大模型取代? 在医疗领域,这个疑问正在被打破。
来自主题: AI资讯
8755 点击 2025-08-29 15:56
 搜索
搜索
不卷参数的专业模型,会不会被通用大模型取代? 在医疗领域,这个疑问正在被打破。
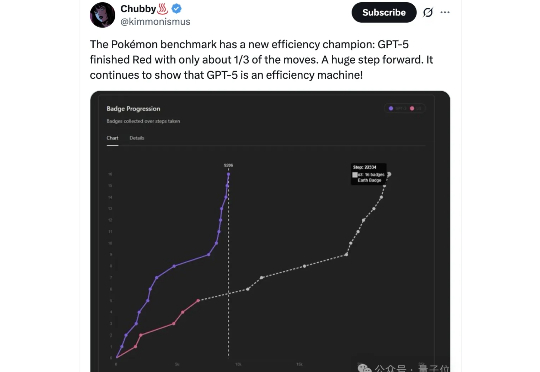
又是一场酣畅淋漓的战斗! 宝可梦主播GPT-5在直播间鏖战一小时,成功击败赤爷(Red),公屏瞬间刷满GG(Good Game)。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
在Openai 发布o3后,think with image功能得到了业界和学术界的广泛关注。

4 个月前,OpenAI 的 o3 模型凭借视觉推理能力模块和智能的进化,在 AI 创投圈子引起新一轮的震撼与海啸,解锁了一大批新的「套壳」创业机会。正如我们在《谢谢 OpenAI,谢谢 o3,新的「套壳」创业机会来了 | 附 12 个潜力方向》一文中预测的那样,VLM 确实带来了新的创业机会。
哦豁,OpenAI奥特曼又痛失一员大将。 Kevin Lu,领导4o-mini发布,并参与o1-mini、o3发布,主要研究强化学习、小模型和合成数据。
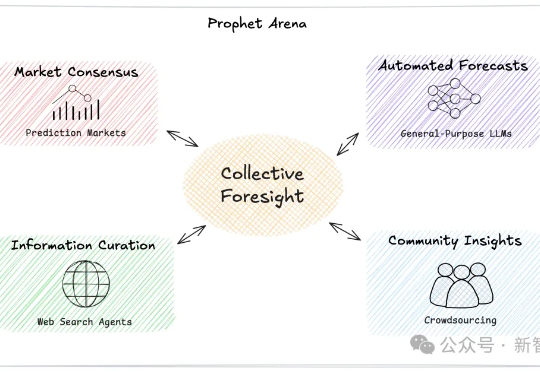
AI能像科幻电影中的先知一样预测未来吗?一个名为「Prophet Arena」的全新基准测试,正通过预测真实世界事件来评估AI的「预言」能力。
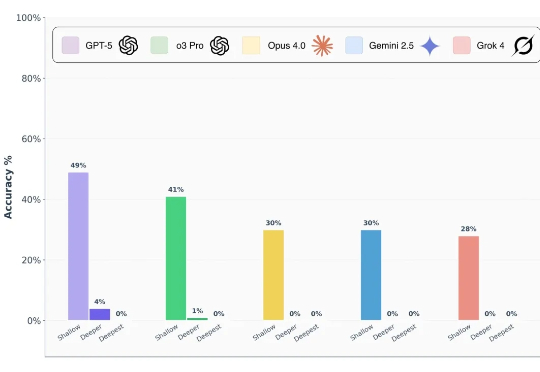
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?
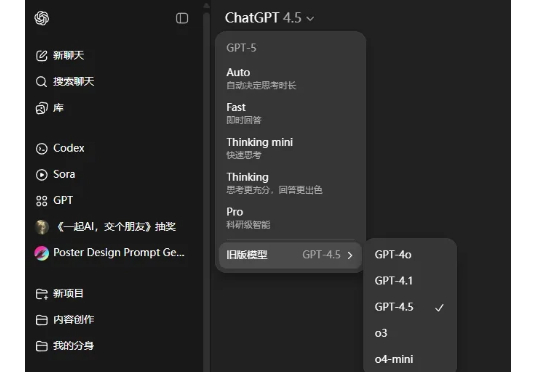
GPT-5和“还我GPT-4o”的风波,闹得沸沸扬扬。 今天,奥特曼还有一次认怂了,不仅调了UI,还把o3这些老模型还了回来。
制作一个视频需要几步?可以简单概括为:拍摄 + 配音 + 剪辑。 还记得 veo3 发布时引起的轰动吗?「音画同步」功能的革命性直接把其他视频生成模型按在地上摩擦,拍摄 + 配音 + 粗剪一键搞定。